

A couple of weeks wading in contextless metrics
A couple of weeks wading in contextless metrics
Data nerd bait

Attention: As of January 2024, We have moved to counting-stuff.com. Subscribe there, not here on Substack, if you want to receive weekly posts.

A couple of weeks ago, I gave in to a very nerdy temptation and bought a Fitbit. Now, those who know me know that I am the most indoor and happily sedentary person in the world. I’m not under any illusion that having a tracking device would make me any more physically fit — I don’t even plan on doing any more exercise than the complete zero I’ve been doing.
Instead, I’ve always been curious just what sort of data could be collected if I were to strap a bunch of sensors to myself and just record — essentially what the ‘quantified self’ folk have been up to for years. Even if there’s no inherent meaning or use behind the data being collected, I just want to see what it looks like as I go about my daily activities.
The other reason I decided to buy a tracker is because I’d never be able to match an actual commercial device in terms of functionality, cost, and form factor. I doubt I can even get a portable skin temperature device running for less than $100, let alone something that’s waterproof, measures a bunch of other things, and comes with a bunch of pre-made analytical tools (which is probably the most important part).
Awash in vanity metrics
When I mentioned getting this device on Discord, someone mentioned that they felt it was not much more than a “glorified step counter” and… they’re not particularly wrong. All the things the device measures don’t seem particularly useful in a practical sense. Mine will track my steps and heart rate throughout the day, but knowing those numbers don’t really change my behavior. While there’s some vague recommendations for taking 10k steps daily and what elevated heart rate levels are good for exercise, they’re likely only motivating for people who like to maximize scores or otherwise want to exercise anyways. I don’t feel any urge to go rack up lots of points at all.
If anything, having metrics just emphasizes my questionable health choices. For example, there’s an algorithm that tries to detect how long I’ve been sleeping based on motion and heart rate data. The results just emphasize my admittedly horrible sleeping habits to the point where I just throw up my hands and laugh at how that’s never going to be fixed. I guess it does answer the question of “how do you find time to have all these hobbies?”

Getting a feel for sensor data
If you’ve ever had the opportunity to work with electronic sensor data at all, you’ll probably know that sensors are extremely fiddly and noisy things. A simple thing like a thermometer can give all sorts of jumpy readings when you just read the values in raw format as fast as you can. Inevitably, some form of smoothing function is applied to the data to make sense of it. It’s mostly an art to pick what sort of smoothing function and how large of a data window to use to suit whatever use case you plan on filling with the data.
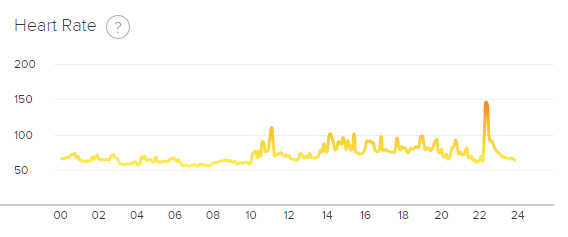
So now, instead of merely having access to a lot of vanity metric data, I get to see how they bounce around in near-real time! I don’t think there is any actual use for this information, but as someone obsessed with counting things it’s very amusing to me. I’m pretty curious what things will look like when I get sick since all sorts of parameters are probably going to go haywire.
If you’ve never had access to this sort of data before, getting some similar device would be a relatively inexpensive way to do so in a convenient form factor.
Access to fancypants analysis algorithms (that might even work)
I don’t have any experience measuring health-related data. So even if I strapped a bunch of sensors to myself, I wouldn’t know how to process them to pull meaningful information out of them.
Just put yourself in the position of one of these sensors, like the accelerometer that’s used to track motion and steps. Think about what kind of magical signal processing needs to be done to turn a continuous stream of very jumpy noisy data into something that resembles a step count. It needs to work while strapped to a person’s wrist (there’s a setting to say whether you wear it on your dominant hand or not because it apparently has a big enough affect on the processing). How do you cover the very wide range of activities a person goes through in a day, from sleeping to daily work, to actual workouts and sports? You’re literally just a blind contextless string of numbers and math! Doubtless, a ton of research went into developing and refining such algorithms.
Then repeat the thing for understanding heart rate data, which is collected by some LED thing shining into your wrist and the reflected light is somehow measured. Then somehow they do analysis to determine whether you’re sleeping or not. The UI even claims to show when you’re in various sleep stages. There’s some studies that say that it’s not super accurate in figuring out exactly when you fall asleep, but it kinda gets you to the rough ballpark. It’s probably enough for users who can’t really do anything with the information anyways. If you have a condition that needs a proper sleep study, get a proper sleep study instead.
So not having to reinvent those wheels to get any use out of things is a very nice feature of buying a consumer product. But it also means that I don’t get to have the (dubious?) fun of reinventing such wheels.
Exporting data (sorta)
Luckily, for those inclined, Fitbit does provide ways to export your data. The base site has a data export section that lets you download data on demand for up to a month prior, in an annoying CSV format and Excel xls. I say that the CSV format is annoying because it’s actually multiple CSV files concatenated together, one chunk of CSV for every section of data you download (Sleep, Activity, Food, etc). It’s not impossible to parse with a bit of preparation, but you can’t just naively do it. The Excel XLS file is honestly cleaner because each section simply gets a separate tab.

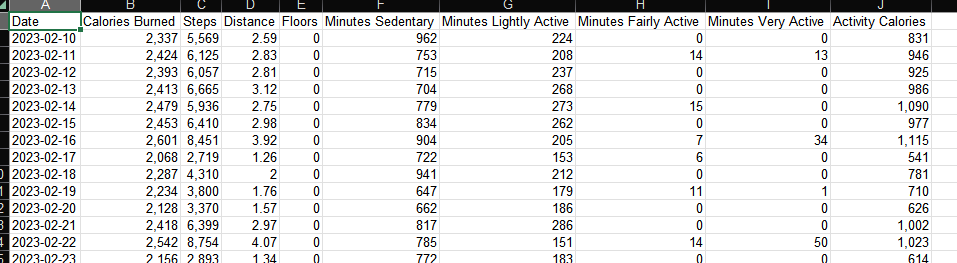
But if you look at the exported data, you’ll find that it’s not particularly interesting to play with because it’s usually daily aggregations of the underlying data. Things are describe as “minutes of activity” for a given day. It’s certainly more efficient and compact this way, and it probably satisfies the needs of a typical consumer user. But it’s pretty boring for me unless I collect a bunch of data over months.
There’s also a way to do a full account export of data, but it requires making a request that sets off an async job to fetch and prepare the data dump. I haven’t taken the time to look at it yet since I’ve only got a small amount of data in there.
There’s fine-grained data out there
So the natural question is… where’s the detailed data? Well, there’s an API for that (Fitbit’s Intraday data API). It promises minute-level data for the interesting stuff like heart rate. Normally I’d be all over the API by now yanking down the data to play with it, but there’s one wrinkle… OAuth 2.0.
Not to derail this thing into a rant, but OAuth 2.0 is probably among the top software things that have caused me endless pain over the years — because it has horrifically bad support for authenticating headless scripts which are the majority of the things I write. The typical flow expects an interactive exchange (typically a browser or a native app solution) to do the authentication bits — and none of my projects have UIs. I don’t even know how to make a UI for anything! I’ve lost track of the number of projects where I happily start planning them out, then get completely stuck at the OAuth2 part. If someone out there has a good library that provides a simple plug-and-play experience in integrating Oauth2.0 with CLI scripts let me know! PLEASE!
Anyways, the minute level data is available through the API and I just have to figure out how to bang on the computers enough to squeeze it out. I’ll probably report back once I have some data around to play with.
So, aside from vanity and trivia, do you find it useful?
I don’t think so. Probably the most I’ve gotten out of it is a slightly increased awareness around what certain heart rates feel like. For example, if I’m walking in the city, my typical pace is what most people would consider “very brisk”, and that actually pushes my heart rate up to around 100sh. That doesn’t feel like “work” since I always walk like that, but apparently it’s elevated enough to count as moderate exercise. Having an external reference point for calibration purposes is nice. Otherwise I haven’t yet found a use for it.
Once I figure out how to download minute-level data from the API I might have some more fun with it as a cute little data exercise. But first I’ll need to slay the OAuth dragon first.
Oh, and while the form factor is actually quite comfortable and unobtrusive all things considered, I detest using it as a wristwatch. The small rectangular screen is only really good for digital readouts and even then it takes a moment to wake up and show me the time. I just wear a proper normal watch on the same wrist.
My complaints might be a different story if I were an active person who regularly goes to the gym. I might actually care about some of the other stats and features then.
Oh, and the privacy aspect
For my part, I’m not particularly worried about this data because it really is just a bunch of glorified step counter data. It’s not great that it’s sitting on some server cluster in the cloud somewhere, but I currently don’t see it as something that could potentially hurt me in the long run since it’s not data that is particularly interesting to advertisers I can think of. I also doubt I’ll be wearing such devices for years and years, where it might provide some weird insurance liability.
Worst case, I’d submit a data deletion request that should nuke my data off of their servers. I can get away with this since I’ve got some trust that the GDPR-like data deletion tooling will probably work as expected. And I only have that trust since I’m aware of how many compliance hurdles need to be overcome for me to even come close to abusing user data at work. Not that there’s any guarantees in a world full of security breaches and sketchy deals.
For other vendors of wearable fitness devices, I honestly have no idea what to expect, so I’ll admit that this whole specific corner of tech is a giant thorny mess of distrust. Having a completely DIY solution (like an Arduino-based one) would fix much of the privacy concerns. It’d make a pretty cool hobby project, but you wind up giving compromising on a lot of stuff.
Anyways, this’ll be a bit of an ongoing project… once I work myself up to figuring out how to log in to get my data. Eventually. Once the procrastination wears off.
If you’re looking to (re)connect with Data Twitter
Please reference these crowdsourced spreadsheets and feel free to contribute to them.
A list of data hangouts - Mostly Slack and Discord servers where data folk hang out
A crowdsourced list of Mastodon accounts of Data Twitter folk - it’s a big list of accounts that people have contributed to of data folk who are now on Mastodon that you can import and auto-follow to reboot your timeline
Standing offer: If you created something and would like me to review or share it w/ the data community — my mailbox and Twitter DMs are open.
Guest posts: If you’re interested in writing something a data-related post to either show off work, share an experience, or need help coming up with a topic, please contact me. You don’t need any special credentials or credibility to do so.
About this newsletter
I’m Randy Au, Quantitative UX researcher, former data analyst, and general-purpose data and tech nerd. Counting Stuff is a weekly newsletter about the less-than-sexy aspects of data science, UX research and tech. With some excursions into other fun topics.
All photos/drawings used are taken/created by Randy unless otherwise credited.
randyau.com — Curated archive of evergreen posts.
Approaching Significance Discord —where data folk hang out and can talk a bit about data, and a bit about everything else. Randy moderates the discord.
Support the newsletter:
This newsletter is free and will continue to stay that way every Tuesday, share it with your friends without guilt! But if you like the content and want to send some love, here’s some options:
Share posts with other people
Consider a paid Substack subscription or a small one-time Ko-fi donation
Tweet me with comments and questions
Get merch! If shirts and stickers are more your style — There’s a survivorship bias shirt!