

A weekend playing with DALL-E Mini
A weekend playing with DALL-E Mini
So. Much. Weird. Artwork.

This weekend I wound up heating my room a bit more than necessary — by running a local instance of the dall-e mini text to image generator model on my desktop machine since the web app went viral and was overloaded.
How to get in on the fun yourself
But if the app’s still overloaded, and you have a decent GPU, you can try running an instance yourself using this dall-e playground tool. From what I’ve seen the code as-is prefers Nvidia GPUs and ideally 8gb VRAM or better. Various people have had issues getting AMD cards to work due to how the ML libraries are compiled.
You can also try running the notebook in the cloud. I’ve heard that Kaggle notebook runtimes have some GPU functionality to them, enough to play with. The model has also been tested on the various tiers of Colab, free (mini), pro (mega) and pro+ (mega_full). But you’ll have to judge whether you want to pay the admission price of those service tiers to meme around for a couple of hours.
In terms of model performance, I saw a pretty big jump in quality going up from mini to mega. The quality gains going to the megal_full model were noticeable but marginal over the standard mega.
Quick intro to the model
Oh, before we go on, I’ll be up front and say that I do not work in AI and 99% of all this stuff is new to me aside from 50,000ft high overview knowledge.
If you read through the brief explanation of how the DALL-E Mini model was trained and built, you’ll learn that it pulls from 3 image datasets:
Conceptual Captions Dataset which contains 3 million image and caption pairs. (2018)
Conceptual 12M which contains 12 million image and caption pairs.(2021)
The OpenAI subset of YFCC100M which contains about 15 million images and that we further sub-sampled to 2 million images due to limitations in storage space. We used both title and description as caption and removed html tags, new lines and extra spaces. (2021)
The general idea is the images are passed to a VQGAN encoder that converts the images into a sequence of tokens. The description for the same image is passed to a BART model that converts it into a second sequence of tokens. Then the two token sequences are used to train a second BART decoding model so that when given the sequence of description as input, it tries to generate a sequence as close to the VQGAN sequence as possible. It’s a method called Seq2seq that originally found use in machine translation (turning one sequence of symbols into another sequence).
End of the day though, as end users of the model, all that matters to us is that the models were trained on image data put together from datasets published in 2018 and 2021 — meaning most popular imagery is probably fair game. Our as users goal is to come up with sequences of words that get sent into the model that are hopefully “close” (in an abstract vector space sorta way) to some artistic notion that generates a cool image.
Learning to control the model
In my mind, because I can’t seem to have fun without overanalyzing everything, toying with the model was a game of understanding what had gone into the training set data and figuring out what the most likely terms were to trigger the effects I want. Given how wide the space of images and potential text descriptions are in the universe, it seems a safe bet that the more well-known and posted onto the internet something is, the more likely it would leave some trace of itself in the model. The model clearly has no idea what I’m asking for if I request some hyper-niche artist or independent game that got zero press coverage.
For my part, I was very curious what artistic “styles” the model had picked up in the data set. I spent much of an evening taking ideas from some of my favorite popular video game franchises and smashing them into as many styles of art I could remember from high school art history class. In the end, I had friends and people on Twitter suggest artists to me and they generally seemed impressed with the results.
When diving in, probably the first thing everyone notices about playing with DALL-E mini is that it does extremely poorly with faces. Most attempts to request anything with a human face (or animals for that matter) will lead to profound disappointment or pure nightmare fuel.

Instead, asking for styles that tend to stylize and simplify faces can lead to more pleasing results. It still generally gets them wrong, but certain styles (like cubism) actually treat the distortion as a feature. I’ve also seen some people add the phrase “from behind” to avoid having faces altogether.
Below, you’ll find a sampling of things I tried:
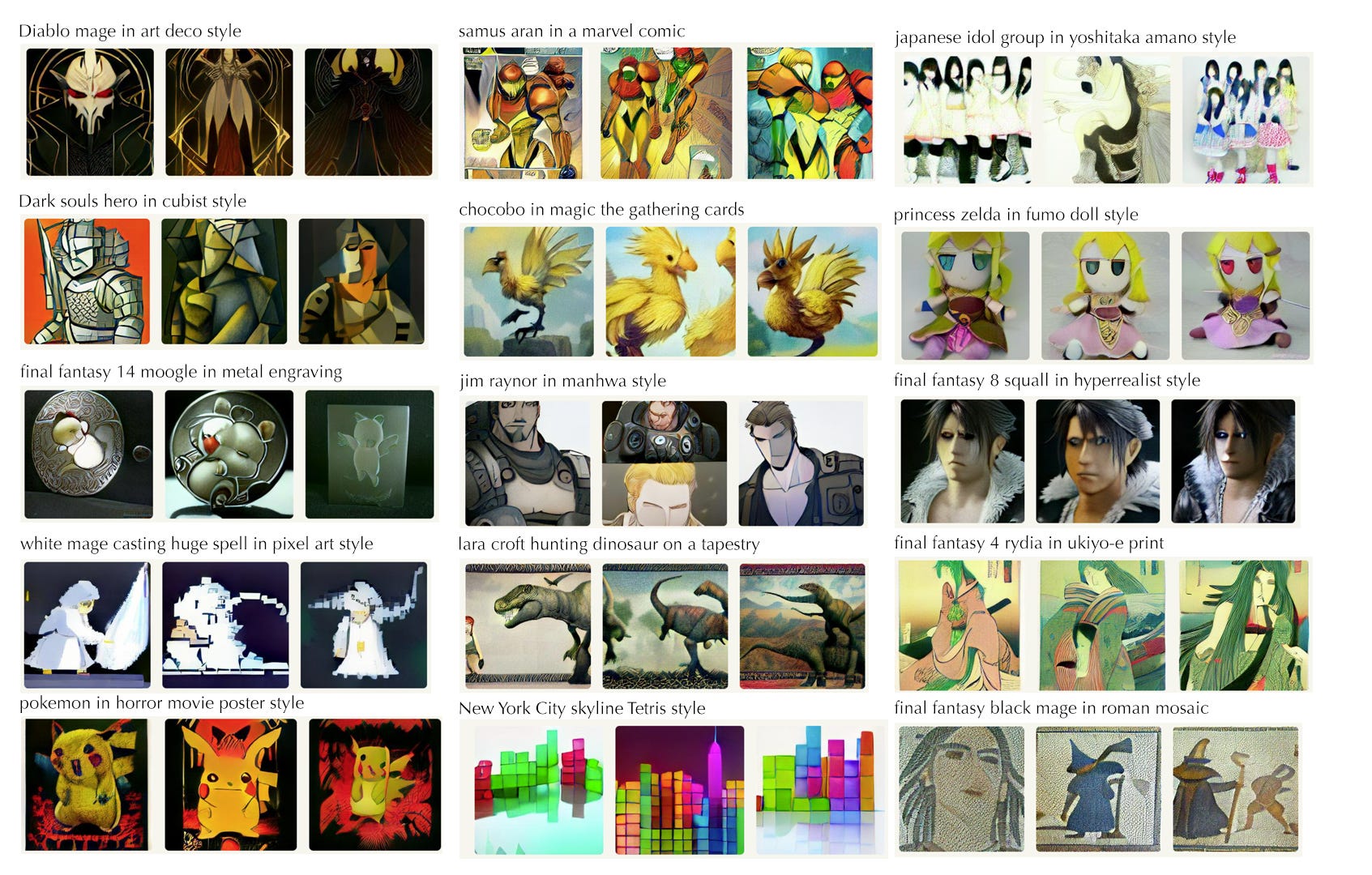
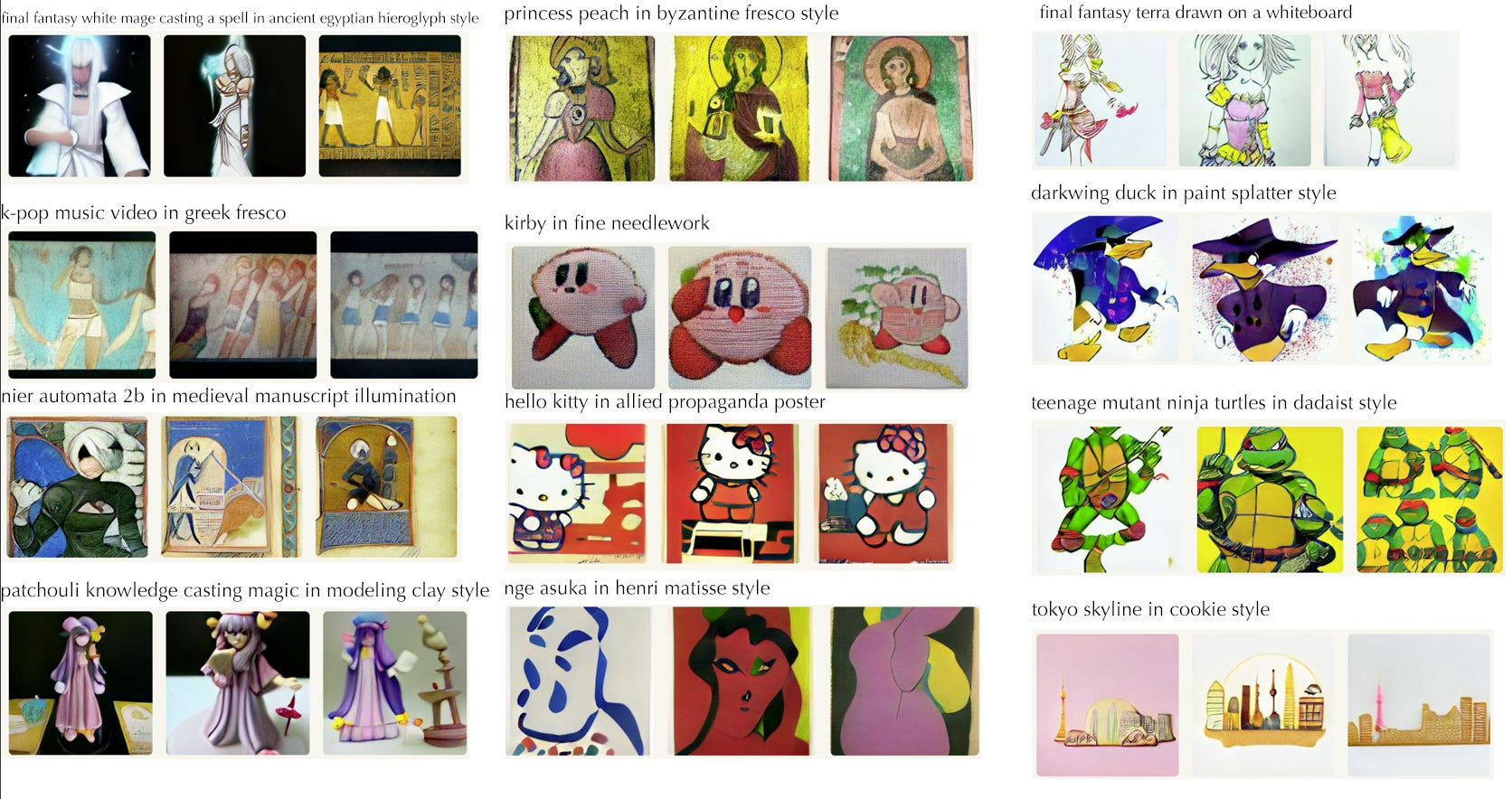
Things I learned
The model has a fairly good collection of artistic styles baked into it. The problem is finding the right words to tease it out. For example, I didn’t know the term for getting ancient Egyptian wall art style, but spamming “ancient egyptian hieroglyph style” hit enough vectors to get close enough for the effect. I still haven’t figured out what keywords would get me the style of Greek amphora pottery, adding “Greek amphora pottery” starts spitting out pictures of jars, but the art on them is unrelated to the rest of the prompt.
If you have a specific artist in mind, and that artist is famous enough that their work is in the dataset with their name on it, you can often specify a style that way. One danger, however, is if an artist is too strongly associated with a particular famous work, like Van Gogh’s Starry Night, it can come up way too often and mess with the results.
Otherwise, more generic terms and actual art periods like “manga”, “hyperrealist”, “roman fresco”, “stained glass”, “impressionist”, “dadaist”, “grafitti”, and “byzantine fresco” will work quite well. I, and others, had some fun generating images with the phrase “magic the gathering” because the art on many of those cards has a pretty distinctive feel to them.
What’s surprising is materials and media can act somewhat like a style descriptor. “wood carving”, “metal engraving”, “in clay”, “marble sculpture”, “in acrylic”, “on a etch-a-sketch”, “whiteboard”, “colored pencil”, and “needlework” all work surprisingly well.
Meanwhile, other people had discovered that the term “trail cam” would yield haunting results, for example if you add Studio Ghibi’s Totoro into one…

The model also surprisingly managed to come up with an acceptable attempt at a “battlemech on a dakimakura”, which I had tried purely for the surreal factor.

Out of everything I tried, my favorite is probably the “sumi-e” style which is just the Japanese term for ink brush painting that has a long tradition in East Asia. The high contrast abstractness of the style seems to work very well within DALL-E’s limitations. I’m also pretty fond of rendering city skylines in “tetris style” and “jenga style”, and the “cookie” and “woodblock cut” styles.


Adding modifiers and other prompt engineering
Aside from the base style, you can tweak the output with tons of extra descriptions. For example, if you change a request for “stained glass” to “cathedral stained glass”, it’s more likely to return tall, narrow, and more intricate windows.
Another useful one is “dramatic lighting” which tends to make subjects be lit with a strong light. Adding “bokeh” will add in blurred circles of light in the background, like you’d find in certain styles of photography. “VHS footage” seems to make everything grainy while adding “4k hd”, “full resolution” or similar tends to get more modern and crisp output.
People are apparently guessing that some of the training data must come from art, photography, and video sites that incorporate tagging data. So if you can guess what other people may tag a picture as with terms like “atmospheric”, you can nudge the model’s output to be closer to whatever those images are. I’ve even seen people add the names of image sites like “Artstation” and “Pixiv” as a way to guide the model.
You can also request specific colors, like a “black background” or “rainbow” to bias the color scheme. Time of day hints like “at sunset” will also affect the colors and composition.
Finally, you can attempt to move the camera in various ways by adding terms like “close up”, “portrait”, “full body”, or “macro” to a query. Adding “symmetric” can be interesting in some situations, though the model generally isn’t perfect in its depiction of symmetry.
As I run out of normal genres (I clearly did not pay enough attention in art history class), I’ve also started throwing combinations of styles, “watercolor byzantine art style”, “art deco manga style”, “paint splatter cameo carving” and the model makes a decent effort at blending the things together. It’s sometimes not clear how two styles can blend together, so it’s hard to judge success, but other times it clearly works.
Other people have started engineering complex prompts like “subject = $thing” and “highly detailed”, taking a cue from what appears to be quirks in the training data to more strongly hint at things.



The one genre I can’t get it to do
Latte art — where people draw things into the milk foam of a cappuccino. I assume there’s just not enough good examples of it online. It’s also terrible at drawing anything resembling a straight line.
Meanwhile, the model builders have generally put various filters and blocks in an attempt to keep out NSFW/lewd and otherwise offensive content from the model. But thanks to “Rule 34”, where there’s internet porn of absolutely everything, there’s a discussion going on about how some people have managed to get the system to render butts. I’m not going to link to it here, but you can find it and similar discussions on huggingface’s discussions about the model.
You can find my ridiculously lengthy thread of explorations here.
Data community stuff
If you’d like me to comment on, or share some data-related work you’re doing, feel free to contact me.
This week, a reader shared a post they wrote exploring how people talk about dating. I found it quite interesting since it’s been over a decade since I’ve stopped dating and language has changed quite significantly since then — for example, what in the heck does “Situationship” mean?!
“What We Talk About When We Talk About Dating” by Joe Hovde
About this newsletter
I’m Randy Au, Quantitative UX researcher, former data analyst, and general-purpose data and tech nerd. Counting Stuff is a weekly newsletter about the less-than-sexy aspects of data science, UX research and tech. With excursions into other fun topics.
Curated archive of evergreen posts can be found at randyau.com.
Join the Approaching Significance Discord, where data folk hang out and can talk a bit about data, and a bit about everything else.
All photos/drawings used are taken/created by Randy unless otherwise noted.
Supporting this newsletter:
This newsletter is free, share it with your friends without guilt! But if you like the content and want to send some love, here’s some options:
Tweet me - Comments and questions are always welcome, they often inspire new posts
A small one-time donation at Ko-fi - Thanks to everyone who’s sent a small donation! I read every single note!
If shirts and swag are more your style there’s some here - There’s a plane w/ dots shirt available!