

Character Encodings —The Pain That Won’t Go Away, Part 1/3: Non-Unicode
Character Encodings —The Pain That Won’t Go Away, Part 1/3: Non-Unicode
How we got here, how we’re not getting out yet, and dealing with it

How we got here, how we’re not getting out yet, and dealing with it
Let us gaze into the madness. (Photo: Randy Au)
Even among engineers, the finer points about character encoding are usually a confusing mystery. For data scientists, it’s even more of an enigma. Let’s learn a bit to prepare for when we have to deal with it in our datasets.
Character encoding, the representation of letters and symbols on a computer, is a problem that will never go away; it can only be made less painful. The reason is simple — so long as humans are unable to read binary and need to read characters, there will always be a need to convert from bits and bytes into characters that obey both linguistic and computation limitations.
The reason why the problem has become a giant pain is because it has been around for over a century. Morse code is a very primitive form of character encoding, and yet a similar mess existed for telegraph codes when dealing with other nations and languages. This long history means that the problem has had plenty of time to accumulate hacks, edge cases, and conflicting standards as technology evolved.
TL;DR Facts About Text Encoding You Need to Know as a Data Scientist
Before we get into the weeds, let’s get the most important facts about character encoding that you need to know out of the way.
“Plain text” is a fiction; it doesn’t exist.
Everything is encoded in some way, including “plain text.”
Guessing an encoding will not work in all cases.
We have Unicode now. Use that. Everything else is legacy support.
These facts will make sense as we go along peeking at the history of how we got here, as well as poking a little bit under the hood.
“Plain Text” Is a Lie — Everything Is Encoded
When people think “plain text,” they’re usually thinking of ASCII, the 7-bit encoding of 128 characters that most modern character encodings trace their lineage to. The problem is that almost no end-user system really uses straight ASCII anymore. Even a bog-stock Windows 7 machine bought in the middle of the U.S. will be using Code Page 1525 — which you might know as “Latin-1” — not straight ASCII. Internally, Windows uses UTF-16 and recommends new applications to use that, too.
“New Windows applications should use UTF-16 as their internal data representation.” — Win32 Unicode documentation
Those curly “smart quotes” that your word processor auto-inserts into your text for you? The diacritics your European friend uses? Those oddly spaced “full-width” texts that came in a spam email? Em-dashes? None of that exists in ASCII, and it means that if you have to handle that text, you need to know how it was encoded to make proper sense of it.
Studying the History of Encoding Doesn’t Help Us
For many things, knowing the history and the context around how and why something was created is often useful for understanding why certain arbitrary-seeming decisions had been made. Sadly, this is not the case for character encodings.
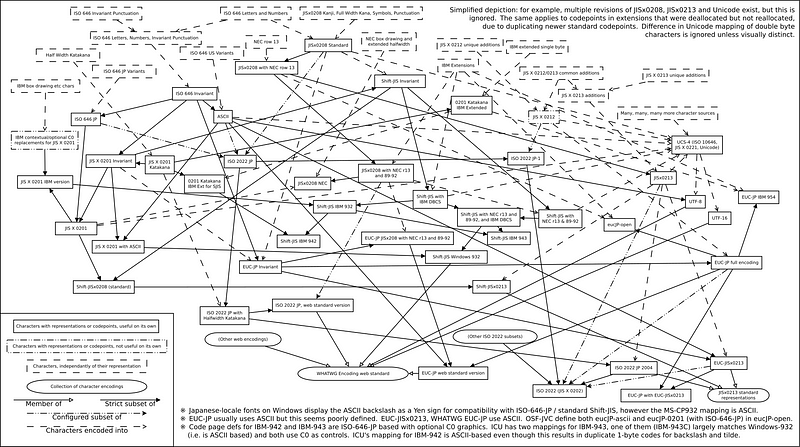
Relationship between Shift_JIS variants on the PC and related encodings, including intersections and other subsets. Source: Wikipedia
At the fundamental level, the chain of arbitrary human decisions that led to the hundreds of code pages and encodings that exist today have no common thread that lets you tie them all together into an easy-to-remember narrative.
Encodings were often created because of local circumstances. There was a need to be fulfilled, maybe with backward compatibility with another system. Inter-operability was much lower on the priority list.
So understanding the history of encodings will just allow you to remember odd details, like the fact that UTF-7 encoding (which isn’t in the official Unicode standard!) primarily exists because legacy email servers only allow 7-bit ASCII and it’s easier than transcoding everything to something like base64. Still, there’s no history lesson that will allow you to fully grasp the nightmare that is the many variations of the Shift-JIS Japanese encoding standards short of rote memorization.
The Ultimate Solution Is Unicode, and Everything Else Is a Brittle, Bespoke Hack
We’ll cover Unicode in the second part of this series, but for now, suffice it to say that the Unicode standard was created to place every single symbol used for written language into a single framework to avoid the collisions that plague code pages.
Unicode achieves this by adding a layer of abstraction between binary bits and the displayed characters. Every character now was assigned a unique code point — that “U+0041” number you’ve probably seen before. Code points are not required (nor intended) to be the actual binary number of the character.
With everything mapped into one namespace, it prevents competing encodings from accidentally pointing to the same thing by accident. Older encoding systems lacked this abstraction, and so people kept using the same sequences for different things. That flaw is exactly why this article exists to begin with.
Under Unicode, various character encoding formats are used to define how binary is mapped onto the Unicode code points. UTF stands for “Unicode Transformation Format,” and this is why UTF-8, UTF-16, and UTF-32 all exist as separate things and encode the Unicode standard. Subsets of Unicode also exist for systems that don’t need the full range of character support.

Wikipedia’s list character encodings
What Code Pages Are and How They’re Handled
A code page is a direct 1:1 mapping of a sequence of bits (a code unit) to a specific character (a piece of text with semantic meaning). It’s a lookup table — a computer sees a bit sequence, looks it up, and displays the appropriate character to the user. Simple.
Early iterations of ASCII were defined with seven bits because 128 binary sequences were all that was needed to cover all the English letters, numbers, symbols, and control characters needed at the time. There’s no a priori reason why “A” is 0x41 in ASCII. It was just worked out that way when they arranged all the symbols they wanted.
Since computers by then were already using 8-bit bytes in the CPU, engineers were quick to realize that there were a whole extra 128 values that could be used. Things started getting crazy when system designers started using the eighth bit of a byte to denote an extra 128 characters. This was initially done without any standardization as local vendors in different countries did something that worked for their local customers.
Eventually, things would be standardized (via ISO/IEC 8859-n standards or similar). But vendors would still create their own variants of the standard for their own reasons (e.g. Microsoft’s cp-932 and x-mac-japanese are based around the Shift JIS encoding for Japanese text).
Remember that all this was happening from the ’70s well into the ’90s, long before the internet connected everything. The chances of one computer sharing bits of data with another computer from another vendor were already pretty low, especially across languages. It was simply easier to ignore the incompatibility issues.
After the dust settled and some standards were agreed on, the concept “code pages” was created. For every code page, the lower 128 values remained the same as ASCII, while the different choices for the upper 128 values would each have their own code page designation. These days, CP-1252/Windows-1252 is the standard code page for Latin scripts on Windows, CP-932 was the Microsoft Windows code page for Japanese, etc.

An example of mojibake Japanese text misread as Latin-1
The end result is that unless the character set was clearly declared upfront, a computer needs to guess what encoding is being used. If the guess was wrong, you’d get Mojibake — incomprehensible incorrect character garbage that makes no semantic sense.
Double/Triple Byte Character Sets, Variable-Width Character Sets Are a Thing
All this time, I’ve only been discussing 8-bit sized code pages. These work fine for many European languages that have fewer than 256 symbols. But Asian languages that make use of Han characters, such as Chinese, Japanese, and Korean, can use tens of thousands of characters. And so, they just need more bits to represent everything.
The solution is to use two bytes (65,536 possible mappings), or sometimes even three bytes (16.77 million) to represent everything you want to display. This creates lots of “room” to map more symbols to numbers, but it becomes more resource inefficient. For example, if you primarily use ASCII characters that live in the first byte area of the mapping, you have a lot of extra bytes that are all zeros.
Since no one in the ’80s and ’90s wanted to spend money paying for storage/transmission for tons of zeros, variable-width encodings were created that would try to use two or three bytes only when needed.
From this, you get the various encoding standards that fall under the ISO/IEC 2022 standard that defined a series of escape sequences to let countries set their own national standards for their language. We get GB 2312, JIS X 0201, KS X 1001, and so on from this. Vendors will implement those standards and oftentimes put their own distinct flavor on top of them just to make life more fun and interesting.
Charset Detection Is an Educated Guess at Best
So, if there are a finite number of code pages and languages are different, there must be a way for an algorithm to figure out what encoding is being used, right?
Sooooorta. But not really.
There are libraries that exist in the world where people who are very knowledgeable about character encodings and international character sets wrote code to figure out whether a stream of bytes was Russian, or Chinese, or Greek.
The ICU (International Components for Unicode) group provides a set of Java and C libraries for working with internationalization. One of the provided components is a charset detector.
Mozilla also created a “universal charset detector” that’s designed to handle the detection of charsets to use in their browser. The linked paper above is an interesting read because it uses statistical analysis and the properties of certain character sets to figure out the likelihood of a given piece of text being a certain encoding. This includes using statistical text analyses of the distribution of Chinese/Japanese/Korean ideographs to help determine which encoding is in use.
Because it’s a statistical method, charset detection works better with larger samples of data. This is why encoding detection can get wonky for very short texts, like tweets. This is especially true if the tweet uses informal language and slang that may skew away from the base corpus data used to build the detector.
Since detection isn’t guaranteed to work, we should always strive to send data with the charset clearly defined. We should also be very skeptical and wary when we have data where the encoding isn’t explicit.
Some examples using Python 3
Python 3 stores strings internally as Unicode — they have a separate byte() type that can store actual binary encoded instances of strings. So, in the examples below, I can force a given string into various encodings and run it through the built-in character set detector. Let’s see what happens.
#Example using Python 3, Pure ASCIIIn : import chardet #character detection libraryIn : s = 'A sample sentence' #uses only ASCII charactersIn : chardet.detect(s.encode('cp1252'))Out: {'encoding': 'ascii', 'confidence': 1.0, 'language': ''}In : chardet.detect(s.encode('cp932'))Out: {'encoding': 'ascii', 'confidence': 1.0, 'language': ''}#Most older encodings show as ASCII because their lower 128 values are ASCII and only differ > 128In : chardet.detect(s.encode('utf8'))Out: {'encoding': 'ascii', 'confidence': 1.0, 'language': ''}#UTF-8 is ASCII backwards compatible and looks like ASCII in this situationIn : chardet.detect(s.encode('utf16'))Out: {'encoding': 'UTF-16', 'confidence': 1.0, 'language': ''}#UTF-16 uses 2-bytes per character, so it is definitely not ASCII compatibleNotice how, because the sentence was written in pure ASCII, the detector (correctly) calls the string ASCII. It didn’t hit any non-ASCII character to tell it otherwise. But my true encoding scheme could be cp1252 (Windows Latin-1), cp932 (Windows shift-jis), or even UTF-8 (designed to be backward compatible with ASCII). In effect, by working naively, the detector will give a correct answer for the string, but it might not be the correct answer for your entire text.
If I had built a data pipeline that wasn’t expecting these alternate encodings, didn’t write proper tests to catch invalid strings, and someone using a different computer with a different default encoding scheme sent data to me, everything would explode once a non-ASCII character came in unless I religiously ran encoding detection on everything. Even if I did run encoding detection constantly, I’d need to make sure all the different strings are handled properly for my back ends.
Let’s take a look at a non-ASCII string.
In : u = u'サンプルです(笑) =D' #actual Japanese text w/ some ASCIIIn : u.encode('cp932')Out: b'\x83T\x83\x93\x83v\x83\x8b\x82\xc5\x82\xb7\x81i\x8f\xce\x81j =D'In : u.encode('utf8').hex()Out: 'e382b5e383b3e38397e383abe381a7e38199efbc88e7ac91efbc89203d44'In : chardet.detect(u.encode('utf-8'))Out: {'encoding': 'utf-8', 'confidence': 0.99, 'language': ''}In : u.encode('utf16').hex()Out: 'fffeb530f330d730eb306730593008ff117b09ff20003d004400'#Notice how UTF-16 is shorter than UTF-8 for storing CJK textIn : u.encode('utf7')Out: b'+MLUw8zDXMOswZzBZ/wh7Ef8J =D'In : chardet.detect(u.encode('utf-7'))Out: {'encoding': 'ascii', 'confidence': 1.0, 'language': ''}# UTF-7 isn't part of the official unicode standard! It's sometimes used for sending Unicode encoded text through emailIn : u.encode('iso2022_jp')Out: b'\x1b$B%5%s%W%k$G$9!J>P!K\x1b(B =D'In : chardet.detect(u.encode('iso2022_jp'))Out: {'encoding': 'ISO-2022-JP', 'confidence': 0.99, 'language': 'Japanese'}# ISO2022 is a standard that defines multi-byte encoding schemes, so versions exist for many East Asian languagesIn : chardet.detect(u.encode('shift-jis'))Out: {'encoding': 'SHIFT_JIS', 'confidence': 0.99, 'language': 'Japanese'}In : chardet.detect(u.encode('cp932'))Out: {'encoding': 'SHIFT_JIS', 'confidence': 0.99, 'language': 'Japanese'}# Shift-JIS and cp932 have a complicated relationship where they are essentially the same, but have a handful of characters that are differentThings get even more interesting when we’re dealing with non ASCII text. Notice that UTF-7 encoding is detected as ASCII! This is because it was designed to be sent through 7-bit ASCII-only systems (like email servers, thanks to RFC 2822 being the base email RFC, and it also assumes 7-bit only text).
Also, notice that it detects some text from cp932 to be Shift-JIS. There have been many flavors of Shift-JIS over the years by multiple vendors and standards bodies with varying levels of backward compatibility. For this particular string, it’s compatible with both, and the detector picked one. The standards disagree on certain characters, and the detector won’t really know until it encounters them.
Notice that each time, the library was super confident (0.99 or 1) that it was correct. Since they were given tiny snippets without any context, there’s no reason for them to think otherwise. Don’t be fooled into a false sense of security.
Charset Detectors May Have Bugs!
Hopefully, you can appreciate that the constantly changing (and sometimes competing) standards for different languages makes for a very complicated universe. Often, unless you’re experienced in working with a specific language, it’s hard to tell how one encoding variant differs from another variant. I work with Japanese occasionally and don’t understand any of these nuances.
Source: Twitter
This sort of problem space makes for fertile ground for bugs. The engineer who wrote the detector might be just unaware of a subtlety or edge case. Or they favored one competing standard over another for whatever reason. Or they’re right and your data source is the one giving output that’s in the wrong encoding.
That means that you’ll hit upon situations where you think you’re going crazy because an encoding error that shouldn’t happen pops up. In such a situation, you might actually be doing everything correctly, and there’s an error external to you.
And don’t think that just because the libraries have been around for years and they’re open-source that these bugs would’ve been found already. Some of these encoding interactions are so rare and system-specific, you might be among the few who will ever come across them.
Use Charset Detection, but Protect Yourself
Hopefully, the above gave you a glimpse at how unreliable character set detection can be at actually detecting the “true” encoding. That’s not to say you shouldn’t rely on these libraries — the answers they gave will allow your code to parse the string at hand (hopefully to convert into Unicode where operations are much safer). The output is the best that anyone can do given arbitrary short pieces of text in a complex landscape.
Instead, what it means is you need to put guardrails in place.
The most important guard rail is to remove the assumption that running character set detection on one substring will tell you the character set for the entire string. Different substrings might yield different results. You ideally want to run detection on the entire text all at the same time for the best results. If you do have to detect strings in pieces, make sure to do it for every single string, no assumptions.
This also means you need to be paranoid and run the detector more often than you originally thought you’d have to. Any time a string leaves your control, you should test.
Finally, when you’re handling unknown encodings, you must be willing to accept that sometimes mojibake will happen. So you’d want to plan ahead a little and leave some room in your code to slip in ways to correct (or at least catch) errors.
So What’s Best Practice?
Use Unicode, duh
The current best practice is to use Unicode throughout your systems, only encoding at the interface between your code and someone else’s. UTF-8 is probably ideal unless you have a strong reason to use UTF-16 (primarily for storage efficiency if you work mostly with East Asian languages). The UTF encodings are encoded in such a way that they’re not likely to be confused for anything else. And so, they’re quite robust on top of the fact that they will encode everything.
Languages like Python will store strings in Unicode, and you only have to handle decoding/encoding the strings at the very beginning when you read data in, and at the very end when you send data out. Practically any modern language that you use these days will have the machinery to handle Unicode (but it might be separate from the native string library, so be careful).
Hop over to Part 2 for the discussion about Unicode.
What if I HAVE to use legacy encodings?
I’m so sorry.
Do everyone a favor and clearly document things, what assumptions are made of text coming in, and what is being output out. This stuff can be mind-bendingly frustrating unless it’s explicitly written out somewhere.
As stated above, write very defensively. Try to understand the range of systems you’ll have to interface with. If it’s a closed internal world, you can more easily control what encodings are supported. If you’re dealing with the wide-open internet, you might just have to force an encoding and throw out errored characters when all alternatives have been exhausted.
It’s also a good idea to leave some way to declare/force a specific encoding without a major code refactor. Sometimes you just know a priori what the encoding is, and you should prioritize that over a detector. Other times, the detector fails and you’ve got to make overrides. Leaving space for that in your code now will save you pain later.
References and Further Reading
Other, smarter, people have done overviews of the encoding problem for engineers. Definitely worth a look. They all choose to cover what they believe is most important, and there’s plenty of overlap, but lots of different views.
Endless Wikipedia pages because the standards are just…
https://en.wikipedia.org/wiki/ISO/IEC_646 — One of the early character encoding standards
https://en.wikipedia.org/wiki/ISO/IEC_2022 — Standard for DBCS/Variable-width character sets, especially for signaling what character plane to draw characters from. Stateful, which causes issues with search/random reads.
https://en.wikipedia.org/wiki/Universal_Coded_Character_Set — The UCS standard has essentially become Unicode.