

Character Encodings — The Pain That Won’t Go Away, Part 2/3: Unicode
This is supposed to save us all, it’s merely the best we’ve got so far

This is supposed to save us all, it’s merely the best we’ve got so far

There’s a light in the darkness… right? (Photo: Randy Au)
Part 1 of the character encoding series is available here.
Before I started working on this article, I didn’t know that the beginnings of what would become Unicode started in the 1980s, with the Unicode Consortium officially incorporating in January 1991 and the first standard published later that year. Just like how the historical problem of character encodings has decades of history, the current solution also has decades of work behind it. Meaning, it’s complex.
In writing this, I had a hard time pinning down exactly what a data scientist even needs to know about Unicode to work effectively. While the standard is extremely technical, deep, and complex, it has also been so refined and well-adopted by the industry over the decades that most of the hard stuff is transparent to the user. It’s amazing how much we’re allowed to take for granted.
What You Need to Know About Unicode as a Data Scientist
Unicode will generally be able to store any character you’re likely to encounter without problems.
As of Unicode 13.0 (draft, as of this writing), there are 143,859 characters in the standard.
Unicode defines a set of 1,114,112 code points, from 0x0 to 0x10FFFF, that can be mapped to characters. The vast majority of which are currently unused and reserved for future usage.
Operations like sorting, regex, etc. are also defined within the Unicode standard, so everything is generally well-behaved, even for things like right-to-left languages, etc. We don’t need to worry about it!
The best practice is to take any incoming text, convert it to a UTF format (UTF-8 or UTF-16 usually), and do all your normal operations in that format.
When converting incoming text to Unicode, try to be sure of the encoding it’s in. Charset detectors are inherently unable to be perfect. (See Part 1)
Only when outputting data for use with the system should you consider converting to a non-Unicode encoding. Even then, 99% of the time it’s better to output to UTF-8.
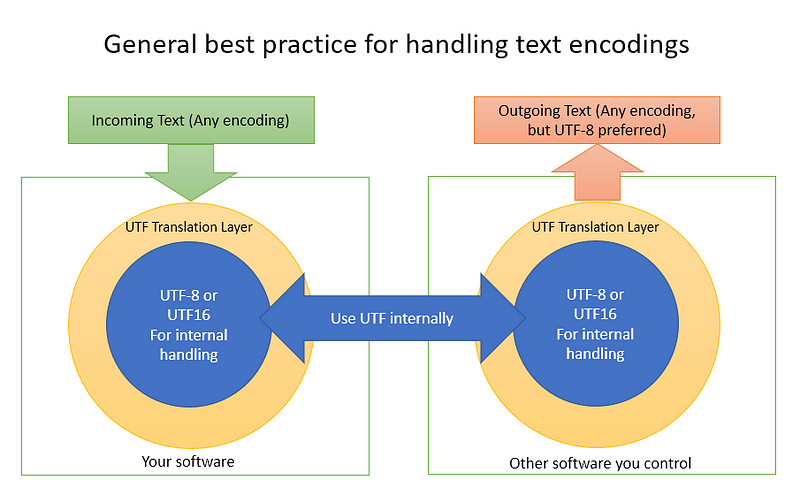
Usually, if you want to handle text input, you should be doing some form of this
That’s pretty much it for anyone who just needs to “handle” Unicode data. For a standard that’s so complex, it’s astoundingly little.
But if We Actually Wanted to Understand Unicode More, What’s There to Understand?
A lot! While we all probably know Unicode as “that standard that works with all languages that we should use,” it’s a giant standard with lots of very interesting parts and useful concepts. Understanding roughly how it works will allow you to better understand how to handle text data.
Let’s peek at the high-level structure and controversial spots!
Unicode Solves the Conflicting Character Encoding Problem by Adding Layers of Abstraction
Like with many engineering problems, adding a layer of abstraction can make difficult problems easier to solve. This is what Unicode effectively does.
Recall that legacy character encodings like ASCII are a strict definition of a binary sequence to a specific letter. In ASCII, 0x41 is the capital “A.” With eight bits, there were only 256 potential numbers to assign characters, and the first 128 were defined by ASCII already. So every code page reused the same numbers for different characters.
Unicode puts multiple layers of abstraction between the binary representation of a character and the actual character than humans intended to display to others.
Layer 1&2: There are abstract characters that exist independent of coding, we code the ones that go into the standard
Unicode seeks to define the encodings of the smallest unit of writing that has semantic value. In European languages, this typically means letters and punctuation. For East Asian languages, this can include thousands of logographic characters. Other languages, such as Arabic, can have more complex rules for writing, like omitting certain vowels or combining characters.
These characters are abstract, like platonic ideals. We need to then bring them down into reality.
(Part of) the table of potential properties a Unicode character can have
This abstract layer exists because there needs to be criteria for “what is a character that should be in Unicode?” When a unit of writing is accepted into the standard, the abstract character is coded, and it’s given a name and code point. Code points are denoted in that familiar U+#### format with hex codes. U+0041 is assigned to “LATIN CAPITAL LETTER A” — the abstract concept of “A,” not the one you see on your screen rendered as a font.
The character is also entered into the UCD, Unicode Character Database, and assigned various properties. Properties are a quiet part of why Unicode works so smoothly — they denote attributes like “being lowercase,” “being a numeric value,” should the character be sorted, and even info for how the character should be handled by the bidirectional algorithms (L-to-R or R-to-L text display).
Coded characters are divided into 17 planes
Unicode is organized into 17 “planes” of 64k code points each. The vast majority are currently unused.
Plane 0: Basic Multilingual Plan, BMP — frequent characters.
Plane 1: Supplementary Multilingual Plane, SMP — infrequent, non-ideographic characters. Historic or uncommon scripts, symbols, etc. Emoticons and emojis live here!
Plane 2: Supplementary Ideographic Plane, SIP — infrequent ideographic characters.
Plane 3: Tertiary Ideographic Plan, TIP — proposed for Unicode 13.0 (still unpublished). Will cover CJK ideographs not covered in BMP or SIP, including many historic characters.
Planes 4–13: Currently unassigned, reserved for future use.
Plane 14: Supplementary Special-purpose Plane (SSP).
Planes 15, 16: Private use.
The 64k code points on a plane happen to be codified using the last four hex digits of the code point, and so the plane is actually an extra digit in front, 0 through F. That’s why the BMP is commonly only shown as U+#### with an omitted 0 in front, while SMP would be U+1####, and so on.
Within each plane, blocks of numbers are assigned to various languages or groupings so that things that share a similar theme; e.g. “Greek” or “Emoticons” are grouped together.
Layers 3&4: Characters are represented in computers and converted to bits
Unicode defines character encoding schemes, like UTF-8, UTF-16, and UTF-32. These define the rules for how computers can use specific bit sequences, — a.k.a. code units — to indicate which Unicode character is being used.
There are multiple ways to encode the same code points; e.g. UTF-16, UTF-32, GB 18030, etc. Some are defined by the Unicode consortium (UTF-8,16,32), and some by other standards bodies. All such schemes encode the same Unicode code points, and thus can (usually) freely translate between each other.
The reason this section is split into two layers is because underneath the UTF layer, there’s another level of abstraction that converts the encoded characters into actual bits and bytes. This is because endianness is still a thing, and different computer architectures will write the same bit sequences in different orders. That needed to be accounted for when you’re communicating data.
What’s With UTF-8, 16, and 32?
The number that comes after the UTF name stands for the size of the code unit that the format works in. A code unit is the minimum size (in bits) an individual character can use.
UTF-8 uses 8-bit chunks to express Unicode. Obviously, there are only 256 values in eight bits, so it has ways to expand to use two, three, or even four bytes to express any characters it needs. It’s also got the very unique property of being backward compatible with ASCII (in that a UTF-8 reader will read ASCII, the reverse won’t work) because the bytes that are used to encode switching to multi-byte are assigned to bytes outside of the ASCII standard.
Similarly, UTF-16 expresses things in two-byte chunks. So if it needs to reach into a part of Unicode that’s not accessible with just two bytes, it will use a second chunk, for a total of four bytes to access it. For historical reasons, many operating systems use UTF-16 in various places internally because Unicode originally was a 16-bit encoding format (then they realized they needed much more room to cover the CJK characters, and had to expand out).
As an aside, UTF-16 has endianness. So you can have UTF-16LE (little endian) and UTF-16BE (big endian). If the endianness is not specified in the name, strings can use the BOM (byte order mark) to specify. The start of the string will have 0xFE 0xFF for little endian and 0xFF 0xFE for big endian.
UTF-32 takes four bytes to express things. But it can cover the entire Unicode standard without doing any of the variable-width schemes that UTF-8 and 16 use. For many use cases, it’s very wasteful (much of the 32-bit space is 0s because most planes are unused) so there’s little use for it. But it’s available nevertheless.
UTF forms are self-synchronizing
The UTF encoding forms are interesting in that they don’t use escape sequences to denote switching to different areas of the encoding scheme and it’s easy to identify character boundaries. This is directly a reaction to the issues caused by ISO/IEC 2022, which had defined escape sequences to denote switching character sets within a code page and were commonly used for CJK languages.
We don’t want escape sequences because it makes strings stateful. You need to read everything in order to make sure you catch the escape character to understand what every subsequent character is. This causes huge issues for searching, concatenating text, etc. because you must scan through the entire string to find all the escape characters.
For whatever you’re doing, just use a UTF format
Overall, most things communicating on the internet use UTF-8. It’s compact if you’re working with ASCII text, which a lot of text on the internet is. If you happen to be working in a CJK language, you may get better file sizes with UTF-16. There’s very little reason to use UTF-32.
ISO/IEC 10646, the Other “Unicode” Standard
Confusingly, the Unicode Consortium coordinates with the ISO standards body so there is a corresponding ISO standard. The Universal Coded Character Set defined by ISO/IEC 10646 is kept in sync with Unicode. It’s common to see people use the two terms interchangeably. But while the two share the same character mappings, there are huge differences between them.
ISO/IEC 10646 defines the Universal Character Set (UCS). It started independently of Unicode, but the two have since become the same thing to coordination. You’ll sometimes see references to the older UCS-2 (two for two bytes), which essentially behaves like UTF-16, for the plane 0 BMP. However, UCS-2 can’t access stuff beyond the BMP. It’s obsolete now.
Instead, the current standard is UCS-4 (four bytes) and is essentially equivalent to UTF-32 but without the extra Unicode semantics that makes Unicode awesome. Clear as mud, right?
Ultimately, the difference between the two is this: The Unicode standard is not just a giant mapping of characters to numbers. It also includes algorithms related to sorting (collation) and regex, as well as encodings (UTF-8, etc.), security (spoofing, etc.), and many other things.
Meanwhile, the ISO standard is primarily just a giant mapping of characters to numbers. ISO/IEC 10646 doesn’t include Unicode’s various properties and algorithms for handling things like encodings and sort orders. So, in theory, something could be ISO/IEC 10646 compatible but not Unicode compatible because it doesn’t implement all the extra stuff.
Emoji
Emoji is all the rage these days on the internet. I still have a soft spot for older style emoticons, though.
(ノ`Д´)ノ彡┻━┻
As you may know, emoji started out as a proprietary text extension for use in Japanese cell phones. They then got adopted into Unicode (starting with 79 in Unicode 1.0) because Unicode strives to include text that is widely used by people, this opened up the door to systems outside of Japanese cell phones being able to use them (assuming the fonts had support for the characters).
Over time, new emojis have been added to the Unicode standard. You (yes, you!) can try to submit a proposal for a new emoji character if you’re so motivated. It takes a significant amount of work to propose and demonstrate that a character deserves to be included in the standard, but maybe someone out there is dedicated enough to do so.
Places Where Unicode Isn’t Magically Perfect
Unicode Just Works™ in the vast majority of cases, to the point where you rarely have to think about it too much. But if you work with text across languages enough, you’ll find some places where it’s not perfect.
Stability policy is a double-edged sword
Unicode is constantly growing. To keep things from being utterly chaotic, they have a set of stability policies. Things like: characters that are encoded will never be moved, names will never be changed, normalization of composition/decompositions, etc.
While this was done so that Unicode stays backward compatible with itself, it also means that certain kinds of errors or mistakes, even in hindsight, will never be fixed. You can find examples in the normalization FAQ; e.g. “ Isn’t the canonical ordering for Arabic characters wrong?” A better way of normalizing was probably possible, but it can’t be changed now due to the stability policy.
Legacy and precomposed characters exist
Unicode has a way to compose characters. You can take e (U+0065) and add a “combining acute accent” (U+0301) to create é. You can also use é (U+00E9), which is called a “precomposed character.” Precomposed characters were put into the Unicode standard to work with systems (and fonts) that aren’t fully Unicode compliant. If the software can’t compose the character from pieces, it may be able to use the precomposed one instead.
One cool thing about precomposed characters is that they are considered equivalent to composed characters. U+0065 U+0301 is equal to U+00E9. They should render the same, and various sorting/search algorithms should treat them identically. This is done via normalization algorithms specified within Unicode.
Composition is also the feature that allows us to have Zalgo text. T͉̥̯͙͒̆ͣ̍̑e̜̭͚͎̱̐͊̃ͥͪ͜ẋ̯̬͍̠̱́̊̔͡t̛̲͇͍͇̖ͦ ͓̙̱̝̮̈́ͨͭt̢̟͙̫̱͉̙̻̔̉̈́̓͂ỏ̖̺̳̘̮̄ͅ ̡̪̱͉̆ͥ̒̐̌̑m̶̽ͭ̓a̛͍͈ͣ͗k̨̟̺̥̝͇̣ͫ̌e̜̳̣̟̫͊̈́ͣ ͖̓͒͌ͭy̵o̬̰͚͍͘u͍͍̲̮ṛ̫͔̆͌̈ͥ ̃̓ͬ͊́̽ͤ҉ë̴͓̠̎ͥͮyͤ̌̃̀ẻ͇̬̰͗͑ͭ͠s̠̗̼͈͎̉̓͌̌̅ ͉̚͟b̟̼̞̦̣̜̾ͅl̤̲̖̫̭̈́̒̂̅́e̱͍e͍̟̹͉ͦ̒͂̊̿͘ͅd͋͛͌͗͢.͇̆̔͐ Go consult a Zalgo text generator if you want to annoy your friends and make new enemies.
Unicode also includes some legacy characters, like U+FB00, ff, two f characters ligatured together. In some languages, this is considered a single character, but Unicode would normally treat it as two with the ligature being a font/presentation issue. But it includes this character so that legacy code pages can round-trip convert into and out of Unicode without issue.
Private Use Areas (PUA)
There are two whole planes (15 and 16), so 128k characters, plus a 6,400 area in the plane 0 BMP (U+E000-U+F8FF), that are designated “Private Use Areas.” These are characters that the Unicode consortium has declared that they will never assign characters to those ranges. Instead, it’s for users to define characters and is defined completely by agreement among users. In fact, if you were to create your own character, arbitrarily pick a PUA code point for it, and convince lots of people to use that character for that code point, you can!
The most common use for the PUA is for CJK languages to define extra characters that aren’t in the Unicode standard. A second group are people, often scholars, who need special characters for unsupported languages. These could be legacy or historic characters, or particular variants. Sometimes, such characters eventually make their way into the Unicode standard. Until then, they’re encoded by agreement among standards bodies, organizations, and font makers. Other scripts and niche characters that may never make it into Unicode can also use the PUA.
But since everything is done by agreement between users, and the Unicode consortium explicitly says they don’t provide any mechanism for users to come to agreement within the standard, conflicts can arise. Two different systems can use the same PUA code point for different characters.
Thankfully, because having a code point doesn’t do very much unless you have a font that also has the character you want to display, it means that there aren’t too many groups out there making extensive use of the PUA. A few groups have published various standards with accompanying fonts. Companies have also used various PUA points for things like including unique logos and symbols in their software or operating systems. Tux the Linux mascot lives on U+E000 in the Libertine font.
PUA characters don’t have any properties associated with them, so it can affect how the character interacts with things like display/search/sorting.
Anyway, while it’s rare to come across these characters, once in a long while you’ll hit them. And now you know why you have weird characters that won’t display correctly without a specific font installed.
Han unification
This is perhaps the messiest and most confusing part of Unicode. Languages like Chinese, Japanese, Korean, and Vietnamese use Han ideographs in their writing systems due to the influence China has had on the region historically. For example, the character 人 is used in all three languages and generally carries the same meaning.
Over the years, through various language reforms and natural linguistic change, characters have picked up multiple forms or different meanings. In Chinese, there are the Simplified characters in use in mainland China, while Taiwan and a few other places continue to use Traditional characters. Japanese has Old and New forms that share some but not all of the simplifications. Korean Hanja is largely similar to Traditional Chinese characters, but they can have their own slight differences. New characters have also been invented in one language and not used in the others.

Some differences are like a game of “Spot the difference.” Source: Adobe
So we have many languages (and even dialects) that conceptually share a set of ideographic characters, but can have significant disagreements over specific details of some of the characters. What may be an old form for one language may be in current use for another, or a character may have slightly different representations in different media or periods of history while retaining the same meaning. What may be a trivial difference in typography to one language may be a more meaningful difference in another. It can get pretty political thanks to the long geopolitical history of the region.
At the same time, the Han characters already use a significant amount of space within Unicode, and it’s not desirable to just include every small difference as a separate code point. So Unicode stuck to the principle of encoding the ‘abstract’ character, treating small font differences as representation quirks, merging characters into one code point where they felt appropriate, and keeping others separate.
Unicode’s handling of this complex “Han Unification” has been controversial. It had to make a distinction about whether certain characters were “different enough” in some way to be included as a separate code point or not. The standard works under a three-dimensional model where they try to include things that are semantically different (x-axis), or have different abstract shapes (y-axis), but minimize the inclusion of things that are merely different in typeface (z-axis). The distinction between y and z differences is thorny. You can check chapter 18 of the Unicode standard for more about all this.
The end result is that Unicode treats a lot of the small differences in how a given character is written as a font issue, and not a semantic issue. For Simplified-Traditional pairs, they have properties linking them together semantically. This has the benefit that it conceptualizes Han characters as being shared across all languages, so if you look up one character in one language, it will let you indicate a single code point to identify a character in multiple languages.
But it also treats regional differences as a font issue, which means that if you mixed Chinese, Japanese, Korean, or even Vietnamese in the same document, you won’t be showing the correct glyph unless you specifically switch to the correct regional font for that language — a fact that runs counter to Unicode’s goal of allowing every language to be used in a single document, perhaps with a single font.
To make things even more complicated, it’s somewhat inconsistent about exactly which characters were deemed to be different enough to deserve getting included in the standard. The Wikipedia page on the topic is mind-bending enough.

Part of the IVD showing some variations
Currently, Unicode Technical Standard #35 has created a way to specify a specific variation glyph with the Ideographic Variation Database (IVD). The IVD is a registry of Ideographic Variation Sequences (IVS, a character followed by a variation selector in the range of U+E0100 to U+E01EF) that selects a different glyph than normal.
Here’s also a thread by someone with MUCH stronger understand of Han Unification than me:
Luckily, We Rarely Have to Think About All This Stuff
As people working primarily with data, we don’t normally have to process text that much (unless you’re into Natural Language Processing, Optical Character Recognition, or similar fields). So we can often rely on our libraries to handle this and work naively with our strings and keep chugging along. Until we have to analyze text directly…
So, for now, it’s nice to have an overview of the complexity that awaits you when you start working out of the comfortable “plaintext” web and start dealing with text that comes from all over the globe.
Some Further Reading for Those Interested
While I’ve put copious amounts of links in the main text body, here’s some more stuff to poke at.
The full Unicode 12.0 standard — Warning, it’s over 1000 pages.
To the BMP and Beyond — A presentation dating from 2005 that explains a lot of the fundamentals of Unicode. Much (all?) of it remains relevant thanks to Unicode’s stability guarantees.
https://www.unicode.org/standard/tutorial-info.html — Tutorials/guides/presentations to the Unicode standard. Some are really in-depth.
Normalization forms — How Unicode will decompose/recompose text to determine the equivalence of characters. For example, here’s 人.
Unihan Database Lookup Tool— Where you can search for Han characters to look up details.
https://en.wikipedia.org/wiki/Comparison_of_Unicode_encodings
https://en.wikipedia.org/wiki/UTF-EBCDIC — A EBCDIC-friendly UTF! For your mainframe needs.