

Data Science foundations: Know your data. Really, really, know it
Data Science foundations: Know your data. Really, really, know it
Know your data, where it comes from, what’s in it, what it means. It all starts from there.

Know your data, where it comes from, what’s in it, what it means. It all starts from there.
If there is one piece of advice that I consistently give to every data person that’s starting out, whether they are going to be an analyst, scientist, or visualizer, this is it.
This is the hill I spend the majority of my time on even now, to the point of obsession. It is a deeeeeeep but eminently important rabbit hole.
But why?
I don’t think I’ve met an actual practitioner who believes being familiar with a data set and the surrounding systems is optional, but it’s something that comes up with people unfamiliar with the field and dipping their toes into the field.
Life isn’t a casual weekend Kaggle entry. Throwing a random forest at your work data is about as effective as throwing a bonsai at your database server. It hurts your server and leaves dirt everywhere for you to clean up.
Your colleagues in business, despite not being data people, aren’t idiots of any sort (hopefully). They’re domain experts that know tons about the business. Don’t be the junior analyst presenting a brilliant new finding to the CEO that gets asked "so did you take out the 3 special high volume contract accounts we have?”, doesn’t end well. Trust me.
What does “knowing your data” mean?
There are many layers to this. I’ll go into each layer in detail. You can also join me in revisiting past traumas at every layer.
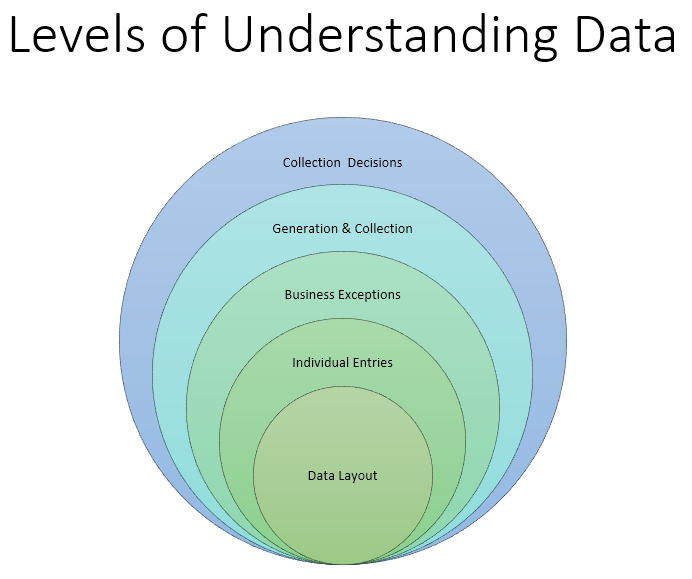
The onion of data knowledge. Things get hazier and more complex as you go out.
The simplest layer is knowing the data layout — where it lives, how it is organized. In a Data Science context this is usually in a database or log archive, maybe a couple of third party services and the defined schema therein. How many data stores are there, what do they hold? What are the fields, what are the table schema and relationships. Basic structure and definition stuff.
Next comes what quirks and traps are within individual pieces of data. Does the data actually follow the schema, are there any strange historic errors and artifacts? Where are the gotchas (there are ALWAYS gotchas).
Then there are business issues about the data. Internal test accounts, special partnerships that have special deals, processing, accounting and security practices that demand specific implementations, etc.
Another step deeper is how that data is collected, where did it come from. What systems generated it, what logic and tech was behind the creation and recording.
Finally, things get really hairy by asking why pieces of data were collected and what wasn’t collected. Why were certain metrics chosen vs others.
How long does this process normally take?
It Depends™
I usually expect that about 3–6 months of querying and using the data set on a daily basis before I feel comfortable enough to say I know the fundamentals of a system that has on the order of a dozen or so critical core tables + a couple of dozen supporting tables. Mid-sized companies/system level stuff.
Obviously, it also depends on how much data exists, how many systems exist, etc. It can take years to “master” a system, only to have people constantly changing the system from under you.
#1 Know the data layout
This is essentially table stakes of knowing what’s available. You simply must know this to even start working.
But scratch a bit deeper and you’ll find there are plenty of nuance involved. Are there foreign key constraints? Is the DB set up like an OLTP or an OLAP? Has the data structure changed much over time, how’d those migrations and updates go? What’s the default text encoding and time zone? (Look, there was a time when UTF-8 wasn’t the default.)
What fields are automatically generated (auto-incrementing fields, sharding schemes, timestamps that auto-update, etc). What are the relevant indexes on the tables. What are the data types and how is everything enforced. (I spent years in a big MySQL and then a giant log environment, this is a huge concern.)
Things get even more Fun™ when you have more complex production environments. DB stuff is here, raw logs go there, processed logs is here, 3rd party tools use another thing, Hadoop lives on another set of boxes, and we have stuff in the cloud too? Do you even have all the credentials to access the stuff? Are they running on the same clock? How the heck are you going to join this stuff together? On what system(s) are you going to join this stuff together? Will you go insane trying to do these joins? (Hint: probably)
Why this layer matters to you
You need to be familiar with all this stuff just to be able to do your job. It’s like knowing where all the ingredients in the kitchen are. Negotiating access can be an utter nightmare in some organizations, and then you have to marshal everything to a place you can do your work.
On a deeper level, there’s often multiple ways to measure something: a sale might be recorded in the data warehouse, but also the base orders table, and it leaves traces in the raw server logs. There’s layers of processing in between, those specifics may be important someday.
#2 Know your data records
The first thing I ever do when I get access to a data table is run a SELECT * LIMIT 5 on it. I don’t usually bother to do a describe. Looking at a handful of actual rows is more informative.
Play with data for long enough and you will hit upon weird things, even within the structured world of a relational database you can find all sorts of quirks. Things get even crazier in arbitrary logs. Some of my more memorable examples that actually happened include:
NULLs just randomly out to get you when you least suspect it, if a field isn’t hard-coded to be non-NULL, I now expect to find nulls
Integers used as bitmasks for storing preference flags because someone on Eng thought it would be nice and compact. Bitwise ops in SQL is a whole extra dimension of fun. Discussions were had
Many timestamp flavors: string ISO with/without tz, microsecond precise unixtimes as 64bit integers, actual timestamps using the internal type
JSON stored as plaintext because the db doesn’t support JSON yet
Truncated JSON because we forgot TEXT fields have finite length
Duplicated ID entries in a system where dupes shouldn’t happen — on a core revenue table
Busted text encoding
Surprise \t, \n, \r, \c characters in useragent strings clogging a csv pipeline
Some jerk managed to put \0 into a thing
Field names that get repurposed for a completely different use because Eng didn’t want to run an ALTER due to downtime. (You know who you are, “logo” field)
Data dumps from gov’t COBOL code on a mainframe somewhere
Orphan IDs because no one really uses foreign key constraints in prod
All the Fun™ you can imagine and even more you can’t
Dealing with this layer
The utter insanity of this layer is why most data practitioners seem to spend the majority of their time cleaning and preparing data. Between bugs introducing erroneous data, malicious/naive users giving you weird data, and occasional bad system design, there’s no end to the list.
We haven’t even considered what happens if you scrape the web, or have to extract data from PDF or “pretty-formatted Excel sheet”.
In fact, my tongue in cheek definition of a junior data scientist is someone who doesn’t violently recoil from the idea of putting an open text box on the internet.
Most of these data issues will likely crash any code you write to do analysis. which is usually a good thing. If you’re lucky (unlucky?) enough that your code runs despite weird data input, it’ll invalidate any conclusions you make and you need to be on-point to realize what’s happened.
When in doubt, ask other people when you see weird data. It’s very often a bug that should be fixed.
#3 Know of business data quirks
Businesses often collect weird special cases along the way, those special cases can trip you up even harder than a random NULL in your ID field.
They’re dangerous because they manifest as valid data points but they behave massively different.
Examples of these I’ve seen include:
Internal users, for testing, employee, or “friends of the business” use. They probably use things differently from everyone else
Strategic partners, maybe they have massively larger quotas and activity and are billed at a discount, or they get features early
Reseller accounts that effectively control 50 accounts worth of activity under one account
Calendars in general. National holidays will mess with your data, month lengths mess with your aggregations. I’ve got a burning dislike for Easter purely because it’s a different date every year and throws YoY comparisons for a loop twice a year
How to deal with this layer
Domain experts and partners all across the business are the key to dealing with this kind of data. All these things are part of the institutional knowledge you need to tap into in order to make sense of the data you see.
The only other guard rail you have is being vigilant about the distribution of activity and users. These special case entries tend to stand out from a more typical customer in some way, so you can hunt them down as if they were a big outlier, then be corrected partway through.
#4 Know where the data comes from, how it’s generated and defined
In science, we’re supposed to meticulously document how data was collected and processed, because the details of that collection process matter. Tons of research has been invalidated based on the fact that there was a flaw in how data was gathered and used. In our case, technology implementations matters here a ton, so break out your Eng hats.
Do you depend on cookies? That means people can clear them, block them, or they expire due to short TTL. People use multiple browsers and devices. A simple example being: “unique cookie” isn’t the same as “a unique human user”, mix those up and you’re in for a bad time.
Do you use front end JavaScript to send events like clicks and scrolls back to your systems? Does it work on all the browsers? Sometimes, remember people block javascript and bots rarely run JS. What is catching the events at home base? What machine records time? Do events fire right before or right after the API call we care about?
If things are being tracked on the database when does the update happen? Is it all wrapped in a transaction? Do state flags change monotonically or freely back and forth? What’s the business logic dictating the state changes? Is it possible to get duplicate entries?
How does your A/B testing framework assign subjects, is it really assigning variants randomly without bias? Are events being counted correctly?
Geospatial data? Have fun with the definitions of metro areas, handling zip and postal codes. Queens County, NY is a aggregation of a bunch of smaller names btw.
IP data? Remember about dynamic IPs, NATs and VPNs , and how it all interacts with mobile devices. Also, geolocations are just very complex lookup tables from a handful of vendors.
Physical sensors? Now you’ve got calibration and wear effects, failures and the real world environment messing with you.
Managing this layer
As you can see, specific details matter a ton. At this point you are checking the integrity of the logic behind the data that exists. You need to be hyper aware of the myriad of biases and bugs that exist in the data so that you know exactly how much you can reasonably say. These details will often make or break a model. All that talk about bias in AI/ML starts here.
Domain experts will be looking for these details, and you should leverage their precious knowledge. It’s hard to beat collective institutional knowledge in this area.
You can help yourself uncover these issues by examining your data carefully, check distributions, question why they look that way.
Over time you should be able to develop a sense of what the engineers were trying to accomplish just by looking at the data table’s structure and data. This is a log of transactions, that’s an audit trail of setting changes, orders go here and can have multiple shipments there. Status codes update this way, and one progression order is guaranteed but this other one isn’t.
With this sense of what a table’s intent is, you can find all sorts of interesting bugs, many of which other engineers won’t notice.
#5 Know the collection decisions being made
All this time I’ve been talking about the data that’s being collected. There’s one big gap still, all the stuff that hasn’t been collected.
Someone made a choice, either conscious or unconscious, to collect one piece of data and not another piece. Knowing those blind spots is important if you’re concerned about biases in your data and models.
Often these decisions stem from practical considerations. Something is impossible to collect, or we decided not to for privacy or ethical reasons, or because we don’t think it would be useful. It’s rarely from open malice, but the effects of misuse of the data can be disastrous.
As an example, we can only collect data about our own users because by definition non-users don’t use our product. There is self selection bias there, and this causes trouble when you are building a new product or entering a new market. Business is littered with the corpses of poor entry into new markets. Then there’s all the extremely disturbing results of algorithms yielding biased and racist results used in very dubious ways.
If you’re aware of blind spots, you can actively take measures to overcome it, but only if you know there’s a problem to begin with. Maybe you go out and collect more data, or re-balance the existing data. Sometimes you just need to conclude that something is a horrible idea and it should be scrapped.
Not everything we do is controversial, but we all use algorithms to pick winners and losers. We have to take that responsibility seriously.
Keep Learning
You’re never going to have perfect data nor perfect understanding of all your data. Just when you think you’ve mastered something, a new feature has been added, standards change, systems are retired. Just keep learning, document what you can, leave paper trails for your analyses and just keep going.