

Hands On: Overdoing a Static Website
Hands On: Overdoing a Static Website
Doing things for the fun of it


This week, I do something I don’t do very often… mess with infrastructure instead of just messing with numbers and databases!
One thing I generally dislike about many technical blog posts is that they present a technical solution to a problem, but don’t go into the technical constraints and preferences that led someone to pick that particular solution. It’s impossible to understand “is this thing for me” when things get presented in a vacuum. This is how you get people running NoSQL databases to power their 5-visitor-a-month blog running on Kubernetes — people saw “a popular solution” and mimicked it, without realizing it was to a problem they don’t even have.
But people rarely discuss the selection process leading to the use of a solution. Maybe because it winds up talking about a ton of “other products” and esoteric historical tech decisions. It would appear to lose focus on the “cool new shiny” at hand. I also assume it’s because it’s a lot of “extra” writing, and people don’t seem to want to admit they made a decision “because I just wanted to”.
But for less-technical folk like me, I find that whole discussion much more interesting. Thus, that’s what I’m going to do. So join me as I walk through the rather wonky chain of decisions that led to the creation of my new personal site (which mostly just holds a curated list of posts from this newsletter by topic).
Motivation: I “just” want a static web site
The impetus for this project is because I often write posts that have a longer shelf life than a week. A post on SQL optimization has been useful for years, not weeks. The problem is that Substack where the posts live, there’s now real way to maintain a curated archive of evergreen posts. So I want to make a simple web site that keeps that list.
To go with this, there are some design considerations:
It’ll be a static web site, primarily HTML and some styling. No PHP, CGI, Django, nothing that does processing upon request. I don’t plan on adding any features of that sort.
I want a default styling/theme that’s at least better than my plain HTML.
It’d be nice to not have to directly write HTML, something like markdown or a similar easy markup language strongly preferred
I don’t want too much maintenance of the infrastructure, if any. No security updates, no server updates.
Cheap is good, because it’s basically 1 HTML file and maybe some CSS.
I also want to learn a few new things today, not just rehash some existing knowledge (see next section)
I want version control
SSL (because browsers like to complain about lack of SSL even when it’s 100% superfluous here).
There’s plenty of ways to do this task
Hosting a static HTML page, even if there’s some framework that converts Markdown to HTML, is pretty trivial stuff. Just put it somewhere that the webserver can find it, make sure the webserver can route HTTP requests to those pages, and you’re done.
In fact, I already know how to do this. I have a small virtual machine running FreeBSD in production that runs Apache 2.4, provides SSL with LetsEncrypt, and hosts some small things involving like Wordpress already. It would take a bit of work to set up an Apache config to handle a new domain and route it to a directory with HTML files. There’s some extra complexity about generating a new SSL cert for the domain, but no big deal.
But there’s some downsides to this method. I’d have to figure out deployment and making it so that if I update the site code in Github, the site updates. That would require having some kind of Continuous Integration/Continuous Deployment (CI/CD) infrastructure going on. Since I’d be running it on a personal server, I’d likely have to DIY it with something like Jenkins. That’d be one more system to learn from scratch, install, set up, and maintain over the long term. I wasn’t up for the task of that today.
If I decided to forget the whole source control integration, I still face issues with deployment. I’d have to get any updated HTML files copied into the right place on the server. Maybe use scp, sftp, or possibly rsync, to copy the files onto the machine like it was late the early 2000s? Or do I log into the server with ssh, pull down the HTML files from git and put them in the right place?
How would I handle little details about having SSH keys, permissions to put files in the right places? Do I really have to do my deployment work from special authorized machines? How would I automate any parts of this without having security secrets scattered all over the globe? There are definitely secure ways to overcome all these problems and more, because other people have figured this out for web sites large and small years ago.
Most importantly, if all this becomes a big hassle I’m going to be lazy about updating the site. Thus, there needs to be some tooling to ease the friction.
Yes, there are services that will do ALL of this for me if I let them
I need to address this sooner than later because I’m sure some of you are probably thinking “oh my god, just use a service like Netlify already.” Because such services offer complete packages — with a free tier — that will take code from git, build it, then deploy it to a web site for you. For the specific use low complexity use case I have, it would all fit easily with their free tier.
Github also offers a similar-ish service called Github Pages, and in fact supports Jekyll, the static site generator I planned on using. Plus, it’s free and I don’t really care if the source code for a list of links is posted publicly on Github. It’s practically all I could want.
The main reason I don’t go this route is because I specifically want to learn about the machinery that goes into such an end-to-end system. It’s hard to truly appreciate the value of services like Netlify that makes it all work like magic, without at least experiencing a sample of the pain it solves. It’s like how I learned to make pie crust from scratch exactly once — it was such a buttery mess that I will gladly pay the few dollars to buy frozen pre-made crusts.
Even if I don’t use a “modern stack” for a web hosting platform, there are tons of providers offering plain vanilla web hosting services where I could just FTP some HTML to an account and I’d have a functioning web site in minutes. It’d just cost significantly more than “practically free”.
Plus, some people on the bird site have noted that I have… uh… masochistic tendancies when it comes to doing certain things like tech infrastructure. As another example, I primarily use vi and vim with almost no plugins when I'm working in terminal because practicing on those will let me use any System V-like Unix or Linux without getting disoriented. I have a long history of bouncing around multiple air-gapped machine environments that has ingrained a need for skill portability.
Now, if I were doing this for work and needed to crank out a site quickly? I would definitely use a paid managed service of some sort instead of doing it DIY.
What I decided to use
Templating engine — Jekyll
Jekyll is a static site generator, written in Ruby. At a high level, it sets up a site file structure, provides a simple templating framework, and will take markdown files and convert them to static HTML for you. I’ve toyed with it briefly before, and I know that I’m perfectly happy using the bog standard defaults for my site. There’s plenty of site generator tools out there, I just picked this one because markdown→HTML is all I needed and had minor prior familiarity.
The only wrinkle is that it requires a compilation step to convert the markdown into HTML. This will have implications will have knock on effects on other technical choices later. In my previous usage, I just compiled and copied HTML files around manually, but it was awkward and I didn’t like it.
Web hosting — Google Cloud Storage
Disclaimer, I currently work on the Storage UX team, which includes GCS here, so I’ve probably seen more of the obscure features from a UX perspective than most people. But on the bright side, if I come across a bit of user experience that needs improvement while I’m using it personally, I know exactly who on my team to talk to in order to help improve it.
One oft-mentioned feature that’s been blogged about for years is the fact that you can use GCS to share files publicly to the internet. You can even attach it to a domain name and treat it like a really dumb web host. That functionality can sometimes be a potential to security issue for larger corporations and so gets turned off, but it’s great for small lazy web hosts like myself.
For completely static web sites, you can use it as a very simple web host. Since my site is going to be a few tiny HTML files, I doubt it will cost even a penny to store and run every month. I also had another static archived web site running under this setup so I didn’t need to do any setup involving billing or anything. It’d be more friction if I had to start fresh.
The setup is well documented on how to associate a GCS Bucket with a domain name, setting DNS to point correctly, and setting the permissions to allow AllUsers to view objects in the bucket. Also users should remember to set the cache-control header on objects going in so that it doesn’t default to the 1hr cache time.
SSL - Cloudflare
One flaw of GCS as static web host is that SSL doesn’t work with custom domains linked to a GCS bucket out of the box. The official solution is to use GCP’s Load Balancer product to provide SSL. But that load balancer is very pricy compared to the $0.01 I was planning on spending.
Luckily, a cheap workaround is to use Cloudflare to handle DNS and act like a kind of CDN. It will give a universal SSL cert for my domain and thus browser will be happy that https works. All for the low price of free because I don’t use any advanced features.
Source code repository - Github
Nothing super controversial here, just needed a place to host my git repo for my site and they’re the de facto standard choice.
Technically if I wanted to stick to GCP (since I’m already using GCS) GCP does offer a source code repository service. I’ve tested using it at work before and it has some nice features to ease authentication if you stick within the GCP IAM universe, but I already have Github SSH set up already for my machines and I didn’t want to deal with setting up a new set of authentication keys.
CI/CD system — Cloud Build, also Artifact Registry
Once I decided to use GCS and Jekyll, I needed to figure out how I was going to run Jeykll to convert the markdown into the site. Luckily, there’s actually some blog posts by various people who have done this exact thing.
In the end, referencing this post and code on github here, it requires setting up two things: 1) a Dockerfile+cloudbuild.yaml that builds an image which has Jekyll installed and stores the image in GCP’s Artifact registry. This is our builder. 2) a second cloudbuild.yaml file that invokes our Jekyll builder image and runs it on our site code whenever Github gets updated.
Cloud Build happens to have a trigger for when a Github repo gets updated. It also has support for various other triggers, but the default setting is good enough for me.
Link curation — Google Sheets. For now.
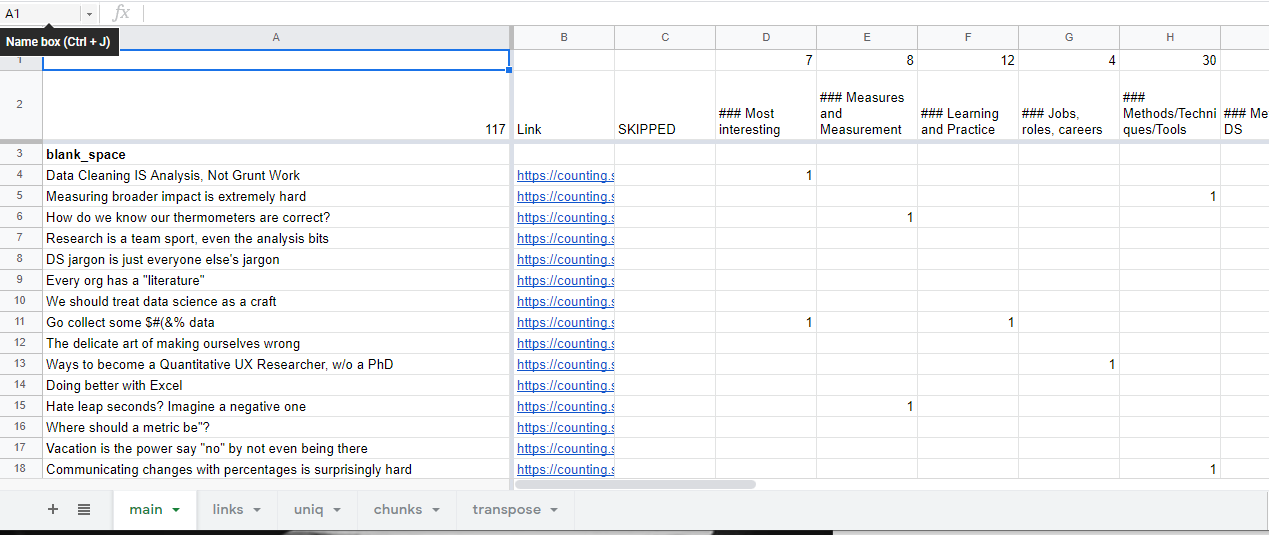
This is primarily because I’m not sure exactly how I want to curate and classify all the posts just yet. So right now I have a big list of every post, a constantly changing grid of checkmarks for proposed classifications (SQL post vs Metrics, etc). Then I have a bunch of formulas that slowly turn them into markdown links which I can just copy and paste into my code.
Obviously this janky process is because I’m not sure how I want to do things yet. It would be a bit overkill to build out some kind of elaborate tagging database until I knew whether a single post can belong into two categories or not, whether I wanted to include everything or just a selection, what sort of ordering makes sense, etc. Since I didn’t have answers to these fundamental design questions, I just punted on the idea and used an ugly temporary solution instead.
How it’s glued together
After a day of reading and fiddling around with the details, I got the site working. The workflow is essentially this:
I pre-build the Jekyll compiler container and it just lives in the artifact registry for whenever I need it
I make changes to the site code from anywhere I want, typically in markdown.
When I’m done, I commit the site changes to git and push it to Github
Cloud Build will trigger due to the Github push. It’ll execute the cloudbuild.yaml file living in the base of that repo.
That YAML file invokes the Jekyll compiler, then it will copy the generated static site to GCS via a simple gsutil command.
It also will use gsutil to set the cache-control header on the newly uploaded objects to only allow 5min of caching instead of 1hr, in case I make updates.
Finally, all the links were compiled into that giant megasheet and the resulting markdown copied and pasted into the page, submitted to git, and automatically deployed.
That’s it. Now I can have a static site that auto builds and is hosted on the web, with SSL. I also don’t have to maintain the builder container except if I somehow need to upgrade the software. Which is unlikely. I can also edit the site anywhere that I’ve set up Github access, which at most will involve logging in and registering a new SSH key. In fact, I could directly edit the markdown files within Github and simply commit the changes there.
I can hear this already in the distance… “O_O WHY?”
All this seemingly unnecessary complexity is because of some of my unique design requirements.
The most important one was how I wanted it to be as pain-free as possible for me to maintain going forward. I am most definitely NOT going to mess with HTML in this day and age. To avoid that I was willing to pay an upfront cost in time and setup figuring things out now (and documenting how things are built when things break in the future).
But in opposition to that goal, which would’ve told me to use a fully managed end-to-end service, I wanted to learn some new tech. That obviously pushes the complexity up. And since I already knew how to run a small, fragile single webserver setup, moving to The Cloud seemed like a logical next step.
So things settled into this quirky balance. At some point in the future I’ll come up with a way to smooth out the classification bit which is the highest friction point
What did I learn?
First, this was the first time I actually examined a Docker file in detail to understand how it works and make tweaks. I had always just understood Docker at a 15k foot high altitude and never looked at the operational details. At most I’d spin up pre-made images handed to me from Ops. Little important details like putting a simple one together from scratch and learning to pass certain parameters into a container by using environment variables were completely foreign to me. I also had to learn about the ghostly infrastructure of container repositories.
Also, while Cloud Build was fairly easy to use given that I had functioning YAML files handed to me, I could see how my job would quickly spin out of control if I tried to roll out my own CI/CD system on the fly. The fact that it worked seamlessly with both Github as well as GCS was a lifesaver. I certainly didn’t have time to learn to spin up a self-hosted CI system in a day on top of everything else.
Maybe that’ll be a project for another day, tied to another wonky need. In time.
I’ve always pondered about a Raspberry Pi cluster running Kubernetes……
Appendix: Relevant bits of code
Here for reference. There are some other files in the linked projects that complete the whole project, but these are the updated/relevant bits I touched to get things working the way I liked.
The Dockerfile for the Jekyll builder, forked from [gordonmleigh/jekyll-cloud-builder] and assumed to get sent to the GCP Artifact Registry in the US via a Cloud Build.
FROM ruby:3.0-alpine
RUN apk add --no-cache build-base gcc bash \
&& gem install jekyll
EXPOSE 4000
WORKDIR /workspace
COPY docker-entrypoint.sh /usr/local/bin/
ENTRYPOINT [ "docker-entrypoint.sh" ]
CMD [ "bundle", "exec", "jekyll", "build" ] and the associated cloudbuild.yaml for the builder image, meant to be involved using gcloud builds submit invocation
steps:
- name: 'gcr.io/cloud-builders/docker'
args: [ 'build', '-t', 'us.gcr.io/$PROJECT_ID/jekyll-cloud-builder', '.' ]
images:
- 'us.gcr.io/$PROJECT_ID/jekyll-cloud-builder'cloudbuild.yaml for the Jekyll site, lives in the root of the Jekyll project:
steps:
- name: us.gcr.io/${PROJECT_ID}/jekyll-cloud-builder:latest
env:
- 'JEKYLL_ENV=production'
- name: gcr.io/cloud-builders/gcloud
entrypoint: gsutil
args: ["-m", "rsync", "-r", "-c", "-d", "./_site", "gs://<bucket>"]
- name: gcr.io/cloud-builders/gcloud
entrypoint: gsutil
args: ['setmeta', '-h', 'Cache-Control:public,max-age=300', 'gs://<bucket>/*.html']About this newsletter
I’m Randy Au, currently a Quantitative UX researcher, former data analyst, and general-purpose data and tech nerd. The Counting Stuff newsletter is a weekly data/tech blog about the less-than-sexy aspects about data science, UX research and tech. With occasional excursions into other fun topics.
All photos/drawings used are taken/created by Randy unless otherwise noted.
Curated archive of evergreen posts can be found at randyau.com
Supporting this newsletter:
This newsletter is free, share it with your friends without guilt! But if you like the content and want to send some love, here’s some options:
Tweet me - Comments and questions are always welcome, they often inspire new posts
Why jeckyll, from your intro I expected details on tech choice.
You may want to check https://sitejs.org/ and tell us about it, it seems like sth one can use for your purposes (get a website and learn sth new) (disclaimer: I did not, yet)