

Life on the abstractions of giants
Life on the abstractions of giants
I love hobbies. This is no surprise to any of you.

Sometimes hobby ideas leads me down strange paths. My brain this week is currently obsessing (as in, it doesn’t want to let go despite a giant deadline rushing at me at 1AM) over 3d printers because there's a handful of oddball projects I want to deal with that I simply can't find a commercially satisfying solution for. Thanks to that obsession, it means that I’ve spent more time researching current hardware, upgrades and modifications, and tools than I have been paying attention to the data world. Thus, this week’s oddball newsletter.
(I should note that this isn’t the first time I’ve obsessed over this topic in the past ~4 years. My hobby research often has a very long buildup cycle.)
I promise I’ll bring at least a tenuous data collection in! It’s something that's always been a mind blower for me — the interface between software and the real world.
For the vast majority of my career working on interior design research, social networks, ads, software as a service platforms, and cloud services, I’m almost exclusively concerned with either measuring data from the real world and translating it into abstract models and concepts. Once the many layers of software and data collection do their thing, I finally have my basic abstract primitives to work with — users, orders, “sessions” (ugh), survey responses, clicks, pageviews.
The abstraction flow only goes one way — Real world → Data → Analysis. The only way that I actually, personally, can affect the real world is by taking my analysis and convincing others (like product folk and engineers) to build something and make it real. It’s only then that people out in the world are affected by my opinions about how things should be, and it’s filtered through a bunch of other people.
Over the years, learning about how to work with the data that I deal with, I’ve built up an intuition about how the underlying business logic tends to generate the data that I see. For example, because I know how some metric relies on browser cookies to be set, I know that a certain (nontrivial) percentage of that metric is misclassified. This sort of domain knowledge is what allows experienced analysts to give useful analysis of metrics very quickly.
But this whole thing about going the other way — taking abstract numbers and data from my computers and applying them to physical hardware to affect the physical world — has left me like fish out of water. I have very little intuition about how various bits of hardware work, and the whole notion that I can write code that can change some voltage down a pin on some chip that ultimately causes a motor somewhere to move is like dark sorcery.
Think about all the layers of abstraction that we as computer users blithely ignore every day in our lives. All our code and interactions that are just ones and zeros zipping through a couple of billion atom-scale transistors in nanoseonds.
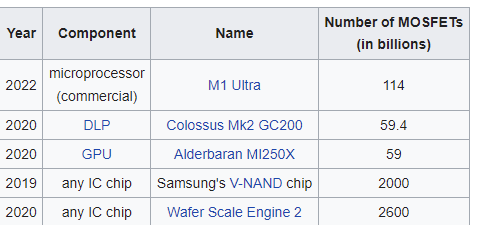
At an even more fundamental level, even those ones and zeros are just high and low voltage values flashing down immense arrays of silicon logic gates. It’s utter magic that my typing on a keyboard translates into electrical representations that eventually cause your screen right now to shuffle electrons around to beam light into your eyeballs. I can’t imagine how many pages of writing would be needed to accurately describe all the abstraction layers that involves.
My platonic world of data analysis isn’t just a mere abstraction of concepts in the world, it’s actually resting on these countless layers of abstractions that include electrical engineering and Universal Turning Machines. We can safely ignore all this almost-philosophical nonsense in data science, and I’m sure electrical engineers never fuss about Turning Machines either, but interacting with hardware decidedly forces me to confront at least some of those abstractions along the way.
For example, the couple of times I’ve pretty radically failed at messing with small microcontroller boards, it’s like learning 3 new (natural) languages at once. It’s being thrown way into the deep end on bits of electrical engineering.
Why is it that if I use this C macro included in the Arduino-like microcontroller’s code that I can send 5 volts down the GPIO pin #4? (No idea, I think it has something to do with the compiler just knowing how to make the CPU do the right thing, and thus it’s just inherited “magic” from the powers that be). How the heck do I understand a spec sheet for a 7-segment display or temperature sensor so that I can do what I want? What the heck is this “wire protocol” and more importantly how do I use it to read what I want?
For 3D Printers, lots of helpful predecessors have put back some user-friendly abstractions in so I’m not dealing with running motors trying to figure out how to spin motors in the right direction and amount to achieve a goal. (For most 3d printer designs, at a minimum you need to manipulate 3 axis motors and one more to print material out, that’s a lot of complication).
Having new abstractions doesn’t make things all that much easier though. There’s entire new tools to learn (3d modeling/design software, “slicers” that convert models into g-code commands that printers/CNC machines understand, as well as a wealth of practical machine tinkering knowledge to know how to fix issues with your machine when things go wrong (because absolutely every one of them will have various issues, the difference is merely in degree).
But aside from having immediate use in doing new hobby tasks, here’s the nice thing about challenging myself with learning all this “low level” stuff — it helps me understand adjacent topics better. Having even the roughest understand that computers are just really complicated circuits of voltages helps put into context why “set pin to high” means sending a certain amount of voltage down a certain wire. That knowledge next helps me read a data sheet that mentions a certain pin needing to be 5V in order to function. The web of knowledge is slowly unraveling thanks to my having found one small piece of knowledge to cling onto.
Enough rambling Randy, come back to Earth here
Abstractions!
They’re essential for working with technology because no one can function from first principles for everything. There’s too much out there. But I want to highlight that we should pay attention to the abstractions we rely upon and put a little bit of energy into understanding them, because there’s lots of learning that comes with all the pain and exploration.
It’s like that “pointless” exercise of hand coding your basic implementation of a machine learning algorithm in class before you start using the packages that everyone else uses. Knowing how it was done “the hard way” gives you appreciation for the current way, while also giving you options for when you have to go off the beaten path to fix an issue.
This also applies to non-engineering things to!
Data scientists, who sit at the intersection of multiple fields, have oh so many abstractions that we rely on from tech and the AI hype. But beyond that small niche area, there’s all the work in research methodology and design, sociological and psychological theories that much of our measurement often patterns behind, as well as a host of other social sciences. When was the last time you stopped wondered how some method or tool you’re using developed or had been applied in other contexts?
It’s a pretty big blind spot that I have to remind myself of on a fairly regular basis. But just like the hobby web of knowledge gets exponentially easier to understand as I manage to digest bits of it, so too does the giant web of data science knowledge.
Stuff I’m sharing w/ the wider data community
“Hundreds of AI tools have been built to catch covid. None of them helped.” An article from July of 2021, but I saw it floating around on my timeline again this week. It highlights a lot of the rushed attempts at applying AI/ML to COVID-19 detection and how it became a giant mess that was ultimately a giant waste of time and resources.
Standing offer: If you created something and would like me to review or share it w/ the data community — my mailbox and Twitter DMs are open.
About this newsletter
I’m Randy Au, Quantitative UX researcher, former data analyst, and general-purpose data and tech nerd. Counting Stuff is a weekly newsletter about the less-than-sexy aspects of data science, UX research and tech. With excursions into other fun topics.
Curated archive of evergreen posts can be found at randyau.com
All photos/drawings used are taken/created by Randy unless otherwise noted.
Supporting this newsletter:
This newsletter is free, share it with your friends without guilt! But if you like the content and want to send some love, here’s some options:
Tweet me - Comments and questions are always welcome, they often inspire new posts
A small one-time donation at Ko-fi - Thanks to everyone who’s sent a small donation! I read every single note!
If shirts and swag are more your style there’s some here - There’s a plane w/ dots shirt available!