

Making Fair Games of Go

Given what is going on outside in right now, levity and distraction are something of short supply. I’m doing by best to get off the COVID-19 blog train, so I’ve decided to expand the scope of “Counting Stuff” to include things outside of just tech and analytics, but still have a bit of a data aspect.
There are many wonderful things in the world that exist and will be fun for us to explore. Hope you, dear subscribers, learn something interesting and perhaps even share some of your own hobbies with me in the comments or on twitter. I’d like to see what people take joy in these days.

Quick Intro to Go
Today we’re going to take one a look at once of the oldest board games still being played today, Go. It also is probably the game with the worst SEO ever. Many search functions on sites refuse to even search for two letter strings and require a minimum of three letters. Things were then made even worse when golang came out in 2009, further clobbering the namespace.
Thanks to the SEO issue, you often have to use the other names of the game, Igo (囲碁) in Japanese from which the English name ‘Go’ derived from, Baduk (바둑) in Korean, Weiqi (围棋 sp./ 圍棋 tr.) in Chinese to search for it.
While those interested in learning the game can hit me up on twitter for a teaching game online sometime, I’ll put the most basic things you’ll to understand the rest of this article here, and leave some resources at the end.
The absolute basics
Go is a perfect information strategy game, much like chess. Two players, black and white, take turns placing stones on a 19x19 grid (smaller 13x13 and 9x9 boards exist for learning purposes, too).
The players compete to claim territory, regions under their control where they can capture any invading stones, that territory counts as points. Whoever has the most points when players agree no more stones can be placed on the board without being captured, wins.
It’s theorized that the original game some 4000 years ago was simply “see who can put the most stones on the board” and the territory concept became a counting shorthand. There are alternate (but ultimately equivalent) way to count the board by counting all stones + territory.
Ranking and Handicapping
Like chess, there is a system for ranking and handicapping so that players of different skill levels can have (theoretically) equal opportunities to win when playing each other. This is the subject of today’s article.
The problem of ranking is a fascinating one from a data science point of view. They’re essentially algorithms that take a set of players, then estimates their relative skill based on historic game performance. The ratings could then be tuned so that handicaps can be given to make games between people of vastly different ratings fair. Fairness of the game is interpreted as a 50/50 win percentage between those two players over the long term.
But life is never simple.
Players can improve (or get worse). New players join the game and are learning very quickly, while experienced players may hit a plateau and are very stable.
“Skill” itself is an complex concept, with potentially many facets. One player could be extremely strong at the opening of the game, but another can dominate in the endgame or tactical game-winning fights. These variances will cause issues for any rating system that gets created.
The traditional ranking system
The traditional go ranking system are used in everyday club and internet play among amateurs. It is generally well understood by all players in all countries despite slight regional differences. It is intimately tied to handicapping and is defined like this:
Ranks are expressed as a number + a tier, for example, 15k, 3d, 2p
Amateurs ranks have 2 tiers, under US/Japanese naming: ‘kyu’ (k) and ‘dan’ (d)
Kyu ranks go from 30 (weakest) to 1 (strongest)
Dan ranks go from 1 (weakest) to 6 or 7 (strongest, highest rank depends on your locale)
Differences in the number part of the rank represent the # of handicap stones the stronger player gives to the weaker player for a theoretical fair game on a 19x19 board. For example, a 3k playing a 8k player will give 5 handicap stones.
A 1d will give 1 handicap to a 1k player.
The final amateur ranking is this: (Weakest) 30k -> 1k -> 1d -> 7d (Strongest)
Traditionally, handicap stones is capped at 9, so a 7d playing a 30k would still give 9 stones. A 9+ rank difference is usually considered a teaching game, not one that is “even".
Pros are so strong that they are live on their own dan ladder (often marked with a p instead of d). The weakest pro is usually considered to be stronger than practically all top amateurs. But occasionally a top amateur may beat a pro in an even game.
There are also many other ways to rank players, and we’ll get to those next. First we’ll note some quirks about the traditional ranking system.
The first thing to note is that ranks are a local phenomena. The system largely works for a group of players that play against each other and establish a pecking order. This was originally how the traditional ranks evolved, where people give handicap to each other as they played successive games. These rank differences can be quite significant. I used to rank about 2d amongst a group of Japanese amateur players, and only rose to about 2k on KGS.
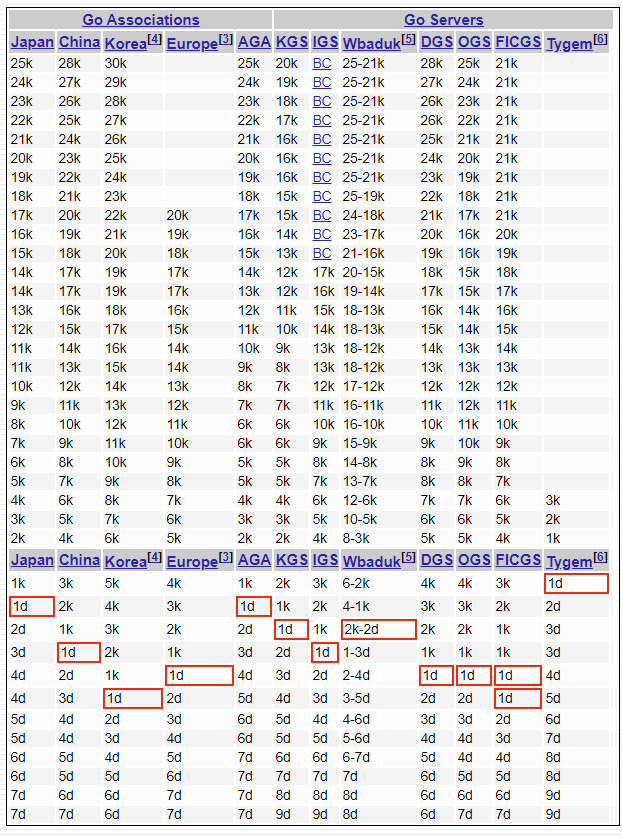
Ranks across different world regions and online servers significantly differ. (Source)
For very early beginners, 30k-20k or so, the variance in player skill is extremely large. They are also unlikely to know how to make effective use of any handicap stones they are given, so ranks in this range don’t mean much. A new player can study and quickly progress out of the lower ranks within a few weeks or months, until they climb to around 15k-10k when handicap games start stabilizing.
")
The distribution of player ranks on an online go server, KGS (Source)
There’s a lot of self selection going on. Many people learn to play, get to something like 23k, get bored, and quit. Player attrition is why the rank distribution graphs all skew to the right.
Rank transitivity is also somewhat questionable. There are many skills to learn and master in the game, a learning player (even a strong amateur) is not exactly the same stength in all of them. So while on average a 2k can give a 5k 3 stones of handicap and with about 50% of the time, you can find pairs of players where 3 stones is the incorrect handicap for that specific pairing, but is appropriate outside the pair.
Finally, just like the weakest extreme can be meaningless, the top end of the scale can get really strange. According to a 6d Japanese friend of mine, he jokes that he’s a “6.5d or ‘strong 6d'“ at home. He can win more than expected against a typical 6d but not enough to get 7d. That 1 stone difference potentially represents a huge amount of work and study. In Japan, amateur ranks cap out at 7d.
This effect can be seen in the pro rankings that go from 1p to 9p. It’s often considered that the difference between pros is about 2-3 stones, so their ranks aren’t really tied to handicap stones. Professional tournament games in the modern era are generally only played without handicap. Typically professional rank promotions are given by professional associations based on career performance (tournament performance, titles won, etc). Unlike amateur ranks, a pro never loses rank even as they retire and are clearly not at their peak.
Other ways of ranking/rating players
People who come from chess are probably scratching their heads about this ranking system. Chess players are much more familiar with FIDE and similar ratings, which often use a form of the Elo rating system which tries to express using probability the chances of one player winning against another player. Elo was the first probability based ranking system to gain popularity, and so many later ranking systems were inspired by it.
Go ranking schemes are usually a bit more complex than chess ones because chess doesn’t have as robust a handicapping system as go. The handicapping adds a new dimension to the data points that need to be fitted by the curves of the ranking output.
Elo systems essentially takes win=1, loss=0, draw=0.5, scales them by a scaling constant (that everyone uses), and uses a probability curve (gaussian, logistic, etc) to determine the number of points Player A should have gotten based on the ratings of their opponents, vs what they actually get. So if Player A performs better than expected, they earn points and rank higher, and lose points if they perform worse. Incidentally, one reason for Elo’s popularity is that it is very simple to calculate, and can be done with a hand calculator.
The European Go Federation (EGF) uses a system based on the Elo rating system, a brief analysis of that system can be found here. Because the EGF system involve winning players taking points away from losing players, one interesting aspect of the EGF system is that the rating points are tuned to be inflationary to account for players coming in, winning a bit (taking points away from people), and then quitting (which over the long term would cause rating deflation).
Meanwhile, the American Go Association (AGA) uses a probability model based on Maximum Likelihood Estimation to derive similar win probabilities, their paper describing the math behind it is here. Essentially they find the set of ratings for all players within the rating system such that the observed game records (wins/losses) is the most likely for their model. The model assumes players have a gaussian skill of μ with variance σ and game results update those parameters. There’s a hard-coded tuning factor in the model that adjusts the expected probabilities of game results based on game conditions (handicap and komi).
Another popular rating system derives from Glicko and Glicko-2 which is a generalized superset of the Elo system. It adds a Rank Deviation (RD) term, which acts as a standard deviation to the rating based on how frequently the player plays. So you might have a rating of 1500 +/-100 due to a 2-RD confidence interval. The interesting thing about RD is that it is designed to widen if a person hasn’t been rated very recently, and tighten if someone plays more and more in the recent past. RDs play a role in point assignment because games against opponents with tighter RDs are weighted more and yield more points. Here’s a nice explanation of how Glicko compares to Elo.
Glicko-2 then adds a second volatility σ figure. Volatility here is a parameter is high when someone has large swings in their rating performance within a period, and low if they perform consistently. Volatility is used to adjust the RD value, essentially if someone plays a ton (which normally tightens RD) but is also very volatile, it keeps the RD wider than it otherwise would be to reflect that uncertainty.
Regardless of what rating system is chosen, the parameters of the ratings models must be tuned to attain the player scaling that the creators desire. They will have to make assumptions about the variance of player skill at different levels (pros would be expected to be more consistent than beginners). The ratings system also needs to account for things like players leaving the game for a period of time and returning. Presumably, those people are more likely to have a different rating (their rating uncertainty increases) because they have either went to learn more outside the system, or haven’t played and their skill decayed with time.
There are tables that can be used to roughly convert a rating into a traditional go rank, since those are much easier to use in day-to-day games.
Rating algorithms are still super interesting today
While it’s easy to think that rating systems for games like chess and go are well studied and settled, the field itself is still extremely applicable and important today. We now have many games, especially video games, that have competitive elements where players play other players. These players must have their skills rated in some way, so that they can be matched with similar players. Games are not fun if one side is being absolutely stomped.
Microsoft had published (and trademarked and patented =\ ) TruSkill in 2007 as a way to extend Elo ratings to games with teams of multiple players on each side. Elo was designed to handle just 2 players that can win/lose/draw against each other, so people have attempted to modify the concept to handle broader situations.
Team games add the complexity that team members are of differing skills. How do you account for those differences to create “Fair” games and also attribute rating increases/decreases to individual players. You can find a recent 2017 paper by Alman and McKay that looks into that exact problem with unique constraints like ‘roles’, queue time constraints, etc. Even the concept of “fairness” evolves because having a low-skilled person mixed into a high-skilled team, or vice versa, might not be a fun experience despite the team having a theoretical 50/50 chance to win.
Overall the problem space continues to evolve simply because new games keep coming up that need their own unique spin on standard rating algorithms to suit their needs. Now games need to make matches given constrained pools of players who are only willing to wait
That’s the fun thing about doing data science on games, they’re artificial, imagined worlds. Our real-world priors may not apply to them at all. So you get to analyze and work with concepts that may only make sense within the confines of that little artificial universe.
Appendix
Nifty resources
There’s a great documentary film about the game, “The Surrounding Game”, which can be streamed on Netflix.
Sensei’s Library is still the largest go wiki around, which makes for good reference material on openings and basic strategy
A list of the more popular online go servers. I rarely play these days, but if I do it’s on OGS or KGS.
One rating (using WHR, whole history rating) of professional go players.
Basic rules of play
The rules are very simple and the game is a great example of emergent complexity.
Players take turns placing stones on the grid intersections
If a stone is surrounded, like if white plays at the triangle point, black would be captured and removed from the board. So long as all lines coming out of a group of stones is filled, no matter how many black stones are connected together, the black stones die
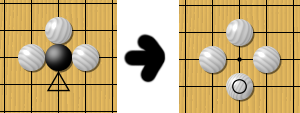
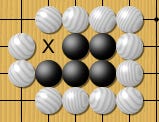
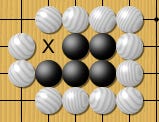
Suicide is not allowed. Black would NOT be allowed to place a stone in that empty single space within the four white stones above. For larger spaces, black can put stones into a surrounded space, BUT the final move that would cause suicide is banned. (Illustrated w/ the X below)
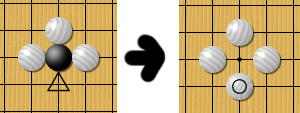
The only time a suicide-like move is allowed to be played is if that move itself is capturing stones, thereby not becoming suicide, such as this:

The above rules all put together allow for permanently uncapturable groups by simply having 2 disjoint spaces, colloquially called “eyes”

There are two interpretations of what the objective of the game is that are equivalent for scoring purposes. One, called “territory scoring”, is to surround as much empty intersections as you can where you can capture anything that tries to enter, your score is the empty points. The other interpretation, called “area scoring”, is to put as many stones on the board as possible, so your score is the empty points like in territory scoring, plus the number of your stones on the board. Under specific rule sets, either scoring method should come up to the same win/loss results.
Whoever has the the most points win. There are no ties because the rules give one player 0.5 points at the beginning of the game as a tiebreaker.


There are of course many more advanced concepts, tactics, small local patterns that you can learn, but they are all made possible by the small set of rules above.