


Organizing Data is Picking What you Care About
And some examples on how to pick

Attention: As of January 2024, We have moved to counting-stuff.com. Subscribe there, not here on Substack, if you want to receive weekly posts.
PyData NYC 2023! Friday, Nov 3, at 1:30pm I’m giving my talk about “Solving the problems in front of you”! It’ll be very much like a 30min blog post, but performed live in person. Come and say hi if you’re attending!

Last week I asked on Mastodon (yes, some data people do use it) if anyone had a topic they wanted me to write about, and got a really beefy suggestion — a really normcore explanation of organizing data for analysis. (I’m often happy to get topic requests so feel free to send ideas in.)

It’s a surprisingly simple question, how should we set data up for analysis. The problem is that simple questions like this lead to ridiculously deep rabbit holes. As far as I can tell, there’s very few absolute wrong answers, just a bunch of messy, conflicting considerations that people juggle while trying to get their work done.
So, in a kind of continuation of my post about how data cleaning is actually analysis, go on a bit about how organizing data is picking what you care about.
Many thoughts on organizing data
It’s impossible to summarize the huge amount of thought that’s gone into the question of how to organize our data for use. The people who wrote many books about the topic have put many years more thought into it than I have. But even if you do the briefest of searching about designing data warehouses or organizing data to begin with you’ll find a set of very common names.
Out in the wild, the notion of “Tidy Data” which surrounds the very robust analysis toolset of R and the “tidyverse” family of analysis tools talks about structuring data in a relatively standardized structure. Data is stored according to three simple rules:
Every column is a variable.
Every row is an observation.
Every cell is a single value.
These rules are equivalent to 3rd Normal Form (3NF) within the context of a single dataset and ignoring join operations via keys. Database normalization is Yet Another Way to think about organizing data, this time surrounding how to make databases better by reducing the chance of anomalous data being stored in a database by putting constraints on how data is stored. This often means organizing things to reduce duplication through the use of join keys and other constraints. Most of us are familiar with 3NF because most databases are designed to conform to 3NF, but there are also higher, more constrained forms that can be implemented, as well as lower, less de-duplicated, forms like 2NF.
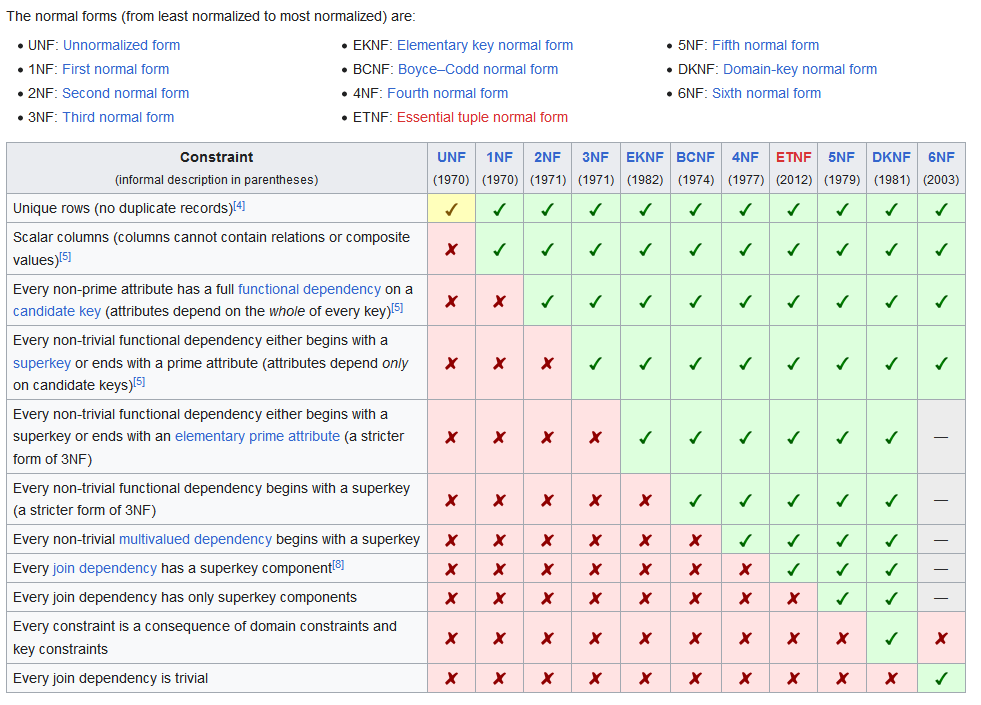
While you’re busy trying to wrap your head around normal forms, you’re bound to come across even more ideas for how to organize data.
You’re very likely to find references to Ralph Kimball and Bill Inmon. The two of them wrote foundational texts about the design of data warehouses (not to mention creating a whole consulting ecosystem around the concepts). The highest level summary I can make is that Inmon’s method recommends merging all data into a giant set of 3NF database tables that can then be later summarized into datamarts that individual teams will access to do their work. Kimball’s method involves business processes creating datamarts around their local data, which are then pulled together into a star or snowflake schema of fact tables that get augmented with dimension tables. The former imposes a shared data structure early on in a top-down approach, while the latter lets teams do what they want for longer, making it more bottom-up.
The above references cover much of the theoretical ground around setting up data for analysis, from small tidy datasets up to multi-billion row data warehouses. But peer within the implementation details and you’ll find plenty of discussion about whether things should be 3NF (or some other normal form), versus having data denormalized for specific reasons.
When designing a data organization scheme, there are lots of choices to make, and what everyone wants is some heuristics to help them make the right decisions for them.
A giant game of horse trading
Let’s take a step back from all the the theory about how we should organize our data and recall why we’re spending so much energy thinking about it in the first place. We want to use our data. We want to apply it to some purpose. We want to analyze it. In order to accomplish our goals, we needed to solve the problems of organizing and storing data for use.
So, just like with cleaning our data, we’re intentionally imposing design decisions upon data for future use. Those design decisions are necessarily going to be compromises of concerns. By enabling certain operations, we’ll be removing the possibility of other operations.
So what kinds of trade-offs are we making?
Note: Even the tradeoffs I list out below are simplified caricatures made for brevity’s sake. These rabbit holes can go DEEP.
When it comes to long vs wide data, we’re fiddling with the space of calculation and human readability. Long data tends to be easier to operate on with code to filter and aggregate, while wide data is typically easier for humans to read and interpret because there’s less repetition and calculation required. Typically it’s preferred to store data that’s intended for further use in long formats, but it’s typically possible to transform between wide and long — pivot tables are a common example of switching from long to wide data.
Database normalization, like 3NF, are balancing a huge array of concerns, and understanding some of them helps in understanding why certain systems happily break normalization.
First off, normalization helps minimize duplication of data within a database. This can take many meanings, but one is making sure that each entry of data is represented by one and only one row in a table. Having this property lets us do our aggregations calculations confidently.
Ever had to worry about duplicated data rows in a complex join that forced you to use a count(distinct rows) statement? Without this type of normalization we’d have to use that pattern much more often. But some systems, like Kafka message queues, allow you to trade this guarantee away in exchange for certain operating characteristics. You can choose to allow messages to be delivered at most once (read: allowing dropped messages) to get the lowest latency. You can choose to allow at least once delivery (read: allow duplicated messages from retries) if you instead want to guarantee delivery. They also offer an exactly once mode that has even higher latency characteristics.
Other forms of normalization focus a lot on eliminating duplication of data within rows and across for various reasons. Instead of writing a user’s name in multiple tables, you write it once in a fact table, then join that information in as needed. This is primarily sold as a way to minimize the need of having to change data in multiple places a user’s name is changed. Such a normalized structure also means schema changes may be easier since everything is linked together using keys so future expansion just means adding more keys. The fundamental pattern of abstraction is already built in.
But the tradeoff for making joins be the norm was that joins can become extremely confusing to work with when you have to join 20 tables for simple tasks. Joins are also very expensive to calculate for extremely large datasets, especially in a MapReduce framework like Hadoop where joins can get awkward to code and require lots of memory. In fact, during the initial decade of NoSQL databases (before everything got a nice SQL compliant interface again), breaking normalization and putting select pieces of duplicate data like a user’s name into every data log entry became a common performance optimization by reducing expensive join work. Engineers looked at the log data being analyzed and realized that the logs would NEVER be updated anyway. If a user’s name changed, we would just roll with the new name going forward in the logs. Database designers of the time realized the tradeoff of “can’t change data easily” for “increased performance” was totally worth it for them since they don’t intend to change data anyway. It also helped that disk storage for the duplicated data was cheap compared to the cost of CPU cores and RAM needed to do really big joins.
Speaking of tradeoffs, we don't have to deal with it as much these days but there were times when data science teams had to work with data off of “eventually consistent” data stores. Those systems traded consistency, where all reads return the same value once a write was made, for availability and latency. That of course causes a lot of headaches and needed special handling. Nowadays, those systems are used for specific tasks and we thankfully don’t typically read off of them for analytics purposes.
Finally, in the debate about designing a data warehouse from the top down or bottom up, the tradeoffs are between implementation complexity/speed and consistency of definitions and metrics across systems which theoretically meant greater flexibility later. The design and code lift needed to centralize everything up front is really really high, especially in larger organizations. Because massive 3NF systems are so hard to execute broadly, in practice I've largely seen everyone take the Kimball approach to things at a high level, but then decide the to what degree they will centralize on a 3NF-style schema at lower levels. Even the most perfectly implemented top-down design is one merger/acquisition away from being a mere “locally centralized” design, so it’s practical to make tradeoffs about making tradeoffs.
There’s also practical matters of setup and maintenance tradeoffs of the tech stack to consider. For example, a standard PostgreSQL database is pretty easy to maintain. It’s a well understood problem with huge community support available. You can even choose to host it yourself or pay some cloud provided to manage it for you for a price. If you need some more advanced operating characteristics, you’re going to have to opt into more setup and maintenance complexity. Running a Hadoop cluster is a bunch of work, as is maintaining a bunch of messaging queues in Kafka.
Throughout all this, you need to keep in mind that a competing technology or design is often created to address some shortcoming of existing options. That typically implies a difference of priorities, and thus a tradeoff is being made. If anything, much of your job is trying to get a sense of what it is you’re giving up.
Picking a poison just for you
I’m pretty sure I just made things more complicated for you in that we went from “I need to pick a way to do things” to “I need to decide what tradeoffs work for me”. For one thing it means you have to go and figure out what decisions make what tradeoffs. It’s not like vendors or product marketing pages tell you what becomes easier/harder with their product. It’s up to your technical knowledge, imagination, and testing to figure it out.
But putting that extra research work aside, it’s usually not hard to think of one or two properties you really care about when it comes to your data. For example, I really care that my data doesn’t have duplicates and I can largely rely on the data to be complete and ready to use within a day. This puts a limit on what architectures I can adopt.
I also have a decent sense of where I care less and am willing to trade those off in exchange for potential benefits. I’ve got plenty opinions about join keys and field types, but can make do with a lot of stupidity there. I care significantly less about the specific schema details and pre-aggregation design so long as I can find ways to get my work done. Maybe giving those up allows me to have simpler data pipelines populating my data.
But even if you have lots of opinions about how you want your data to be, there’s still a huge gray area were you just can’t tell which is more important. Yes, latency is important to me, but is it “volunteer to deal with eventual consistency issues” important? Storage cost is important to me, but is it enough to rule out using a few choice denormalized fields? It depends on specific circumstances that only you can answer.
But if you still have no idea what tradeoffs to pick, go with the one that is easier to maintain over the long term. Why opt into a tradeoff that makes your life harder without getting a clear benefit.
This is why a lot of veterans will recommend that, without clear reasons to the contrary, people start implementing data systems with a simple Postgres database to start. It’s inexpensive, powerful and robust enough to handle a surprising number of use cases on modest hardware. You can focus your energy on the data model first, which probably has bigger usability implications. By the time your scale demands you switch off to something else, you’ll have developed a much better sense of what tradeoffs you’re actually willing to make on the tech-stack side.
I remember almost 10 years ago, some university students presented a data project they did for school at a data Meetup event. It all went well and afterwards a few of us stayed to ask them how their stack worked. They then started saying how their MongoDB setup kept breaking and causing them trouble. A bit of questioning and we learned they were only manipulating about 50k data points. Everyone who stayed behind unanimously recommended they just put their data in Postgres and worry about “going webscale” later.
Lazy defaults
Before I throw you back to the realm of totally overthinking how to organize your data along more dimensions than you had originally considered, here’s my internal list of default start points for a random data project:
Data in “long” format, one row per observation/event
Record at the level of detail that lets you talk about your unit of analysis reasonably
3NF for all the tables is usually good enough
Use a typical star-like fact-table, log-like-dimension-table setup with integer join keys linking everything together
Shove everything into a bog standard relational database, yes you can even shove log data into if you want
Upgrade the database hardware when you hit a bottleneck while it’s cheap to do so
A basic data collection setup like this will probably get you into a couple of million of rows of data without any trouble for most common use cases. Even if you have tons of log data being generated to disk, you can temporarily load chunks of the data into the database for easier analysis until you figure out exactly what you want to do with your logs. If you’re in a situation that requires a different starting setup than this, you probably already have an idea of why it won’t work.
With this setup, you’ll at least have something to trade away in exchange for other benefits. Switch to Hadoop if you want an open source platform with as much disk as you need. Switch to one of the big managed data warehouse solutions like Snowflake or BigQuery if you would rather not manage a cluster yourself and can afford the price tag. Denormalize your data when you hit bottlenecks. It’s all up to you, but you’ll be solving real problems instead of imagined ones.
Standing offer: If you created something and would like me to review or share it w/ the data community — just email me by replying to the newsletter emails.
Guest posts: If you’re interested in writing something a data-related post to either show off work, share an experience, or need help coming up with a topic, please contact me. You don’t need any special credentials or credibility to do so.
About this newsletter
I’m Randy Au, Quantitative UX researcher, former data analyst, and general-purpose data and tech nerd. Counting Stuff is a weekly newsletter about the less-than-sexy aspects of data science, UX research and tech. With some excursions into other fun topics.
All photos/drawings used are taken/created by Randy unless otherwise credited.
randyau.com — Curated archive of evergreen posts.
Approaching Significance Discord —where data folk hang out and can talk a bit about data, and a bit about everything else. Randy moderates the discord. We keep a chill vibe.
Support the newsletter:
This newsletter is free and will continue to stay that way every Tuesday, share it with your friends without guilt! But if you like the content and want to send some love, here’s some options:
Share posts with other people
Consider a paid Substack subscription or a small one-time Ko-fi donation
Get merch! If shirts and stickers are more your style — There’s a survivorship bias shirt!
Great take. Reminds me of a really good grad school seminar kickoff.