

Paper reading time - Forgetting in Data Science
Paper reading time - Forgetting in Data Science
There's a lot


This week, Twitter proved itself useful by plonking this on my timeline — a paper presented at CHI 2022 on “forgetting” in data science. The paper is available to read here. It’s a relatively short read, but on the dense, harder-to-parse side for me because it taps pretty deeply into a literature I’m unfamiliar with — I didn’t realize there’s a lit for critically evaluating what we data scientists do.


What caught my interest about the initial abstract of the paper was how it seemed very relevant to how I just recently wrote about data management is primarily about managing context. I’m primarily concerned about how context fails to be preserved when data is passed along step by step in the data analysis process. That is to say, I think that it’s very important that data work has a “paper trail” that traces all analyses back to the original data collection process. Without the paper trail (and sometimes, even with it) we can never be sure we rest on sound analytical footing because we won’t know what hidden biases and flawed assumptions lurk within our data.
That line of thinking is effectively the same as (some of the) “forgetting” that this paper lays out in their taxonomy. But since it’s a piece of academic work and not a weekly unresearched newsletter post, the authors are much more thorough with their thinking and typography than I could ever hope to be.
“Forgetting”
The central theme of the paper is the concept of forgetting and how data scientists can “forget” things (as in, be unable to recall a bit of information/knowledge) during their work.
The authors give examples that forgetting can be potentially a bad thing — for example, if the details about how a survey sample was determined and implemented will have bad implications for how it can be used (if it should even be used at all) —this is how we generate bad analyses based off “publicly available data”. Forgetting could also be bad in instances like how a dataset could be completely silent on a whole population segment.
The authors also point out that forgetting can sometimes be a good thing — for example, modern data warehouse systems like BigQuery, Snowflake and friends lets us “forget” all the implementation details of coding things like MapReduce or distributed algorithms so that we can focus on doing our real work. Forgetting can also be good in that if I receive data to use from someone else, I have the choice to choose to trust that researcher’s work and “forget” the analytical choices made by the researchers before me (note, ‘forget’ here is from the perspective of the analysis, I’m essentially being willfully ignorant out of convenience.).
Below is the table that the authors provided summarizing the different types of forgetting that they’re covering.
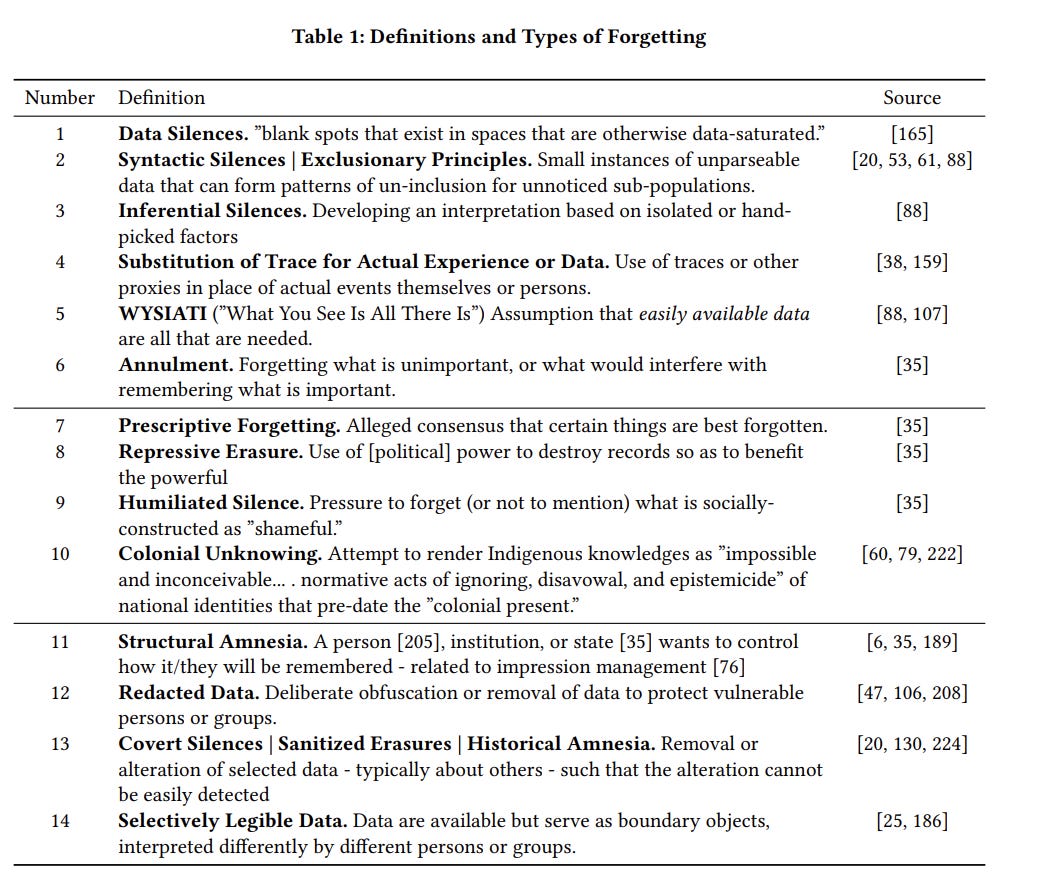
The authors describe the three broad groupings of types thusly:
We divided the rows in Table 1 into three groups. The silences in the first group of rows (1-6), ”Modest Silences,” are often relatively innocuous actions that are likely to happen, but without negative intentions.
The silences in the second group of rows (7-10), ”Silence as Force,” are more deliberate, and may represent intentions to erase or obscure information to the disadvantage of others.
The silences in the last group of rows (11-14), ”Ambivalent Silences,” are complex actions that may be done for mixed or uncertain motivations.
Context is important to interpret any of these silences, but is particularly important for the silences in rows 11-14.
— pg 3, section 2.3, sentences placed on separate lines for legibility, but otherwise unchanged
My biggest gripe with the list is probably superficial — while the authors roughly break the types into 3 broad categories, the entries themselves are still an unsatisfying mishmash of examples. If you scan the list, there’s some assumptions people can make about data, acts of deliberate censorship, silence, or sabotage, mistakes made during analysis, and more. I suppose my main desire is a “theory of forgetting” from which I can shoehorn this typology into as well as make predictions for other issues. It also helps me remember things in my very limited working memory.
I should be clear that this paper never promised to do anything more than lay out broad list of forgetting practices.
If I were try to group things up into themes better, I’d probably have buckets for:
Data collection choices, whether they’re recorded, hidden, or lost, intentional or unintentional
Analytical choices, how cleaning modified the data and affects things downstream
Wrong assumption, often made out of ignorance, assuming the data has some properties/completeness that isn’t true, and how this can “telephone” downstream
Deliberate data modification, whether for benevolent, malicious, or arbitrary reasons
I think those themes cover most of the cases, though it’s far from perfect (for example the line between malicious data collection and data modification isn’t particularly clear)… I suspect there are multiple dimensions to building a theoretical taxonomy, including along an axis of “where/when it happens — collection, analysis, model building, etc”, “what’s being forgotten, data, process, analysis, etc”, “how it changes subsequent analysis”, “who it’s benefiting”, and probably many more. It’s certainly too much for me to muddle through alone on a single Monday night.
Where it gets interesting for us - there’s more things for us to worry about
I’m going to skip over most of the stuff in the paper because I think it’s worth a read for everyone. The authors describe an example data science “stack” going from data collection to building an ML model and use it to illustrate the many places where forgetting can happen as data and analysis flows from one stage of work to another. They also describe and give examples of all the entries in the typology, with copious references to the work of other researchers.
Instead, here’s what I think is important for us practitioners.
As I mentioned in the post about how context needs to move along with the data because we can’t do our jobs properly without being able to refer to the context later. In light of how this paper frames forgetting, preserving context only solves part of the problem. My way of framing “context” is mostly tied to the practical code, queries, assumptions used in working with data, as well as notes on where the data came from and how it was collected. It’s documentation for our data science work that’s analogous to docs, the source repository, and changelogs. The assumption is that, if we’re better about our recordkeeping practices, doing data science can be easier and better than they are now.
But my simple discussion about context pretty much assumes a neutral, if not largely benevolent, environment. What if we’re working in problem spaces that are more challenging? What if there’s downright malevolent actors in the mix? A lot of the data coming out of government and society have a mixture of well documented, and completely undiscovered, biases and flaws to them. Some of those issues are practical limitations or mistakes, while others are going to be intentional. There may have even been efforts to conceal that data had been biased in some way for some purpose. How many data scientists working with data sets are even considering such a possibility?
Very often, data scientists aren’t equipped to identify that such situations exist. Math, after all, works no matter what garbage we shove into it. Discussions about ethics in AI/ML is at least trying to raise awareness about some of these issues, but what percentage of data scientists are engaging with that relatively new discussion? There are so many of us who never work with ML models I would not be surprised if the majority of practicing data scientists are oblivious to even the broad strokes of the conversation.
And so, it’s probably even more important that we need to be very aware of, and actually check, that our data and analyses are resting on solid foundations. That’s going to involve a lot more uncomfortable critical thinking on our part. I’m not even sure if there’s much tooling around to help us search for screwy issues in our data and analyses — there’s certainly no easy magic bullet solutions.
How exciting, to constantly live on the edge epistemic chaos.
Standing offer: If you created something and would like me to review or share it w/ the data community — my mailbox and Twitter DMs are open.
About this newsletter
I’m Randy Au, Quantitative UX researcher, former data analyst, and general-purpose data and tech nerd. Counting Stuff is a weekly newsletter about the less-than-sexy aspects of data science, UX research and tech. With excursions into other fun topics.
Curated archive of evergreen posts can be found at randyau.com.
Join the Approaching Significance Discord, where data folk hang out and can talk a bit about data, and a bit about everything else.
All photos/drawings used are taken/created by Randy unless otherwise noted.
Supporting this newsletter:
This newsletter is free, share it with your friends without guilt! But if you like the content and want to send some love, here’s some options:
Tweet me - Comments and questions are always welcome, they often inspire new posts
A small one-time donation at Ko-fi - Thanks to everyone who’s sent a small donation! I read every single note!
If shirts and swag are more your style there’s some here - There’s a plane w/ dots shirt available!
"Wrong assumption, often made out of ignorance,"
I used to have a whole lecture for young Geophysicists on what could go wrong with the data they received. In a way it was a paean to an old manager I had had who had gathered all of us youngsters together one day and said "kids, I just want you to know, that should not trust the data you get from other disciplines. You understand the problems and limitations of seismic data, but let me tell you, all those other data sources have just as many problems. Ask questions, don't accept their data blindly".
It was one of the more useful pieces of advice I received in my career.