

Path dependency is important to know
Path dependency is important to know
Knowing how you got into a situation can help you get out

Thanks to a frickin’ coup attempt happening last week and the increasingly horrifying wave of news and details following it, I barely got any work done and that state is likely to continue for a period of time. Thus, no continuation of the Eclipse post from last week because I can’t concentrate. But I did promise myself that I will post one thing a week, so instead I’ll riff off some themes that came up during the course of life this week.

This week I want to write a bit about path dependency, because as someone who works on products and has to guide where a product will be headed in the future, it’s an important concept.
The basic, overbroad, idea about path dependency is that “history matters”. That is, decisions being made today have been influenced by decisions and events in the past. The implication is that the best/most rational solution for a given situation might not be chosen, or even available, due to historical reasons. The path taken to reach a certain point has lasting effects. It’s a concept that pops up within the social sciences, especially political science and economics.
Ever have the conversation where someone asks “Why don’t we use Hot New Tech T?” only to find that the answer is “Our tech stack is built on P which predates T’s stack by 5 years and we’d have to rearchitect the whole app. It’d cost too much for no benefit.”? That’s an example of the effects of path dependency. Even if Hot New Tech T is the clear winner, there are historical barriers to adopting it.
If everything was built in Java because the codebase came from an enterprise environment built in the mid-2000s, you’d need a HUGE compelling reason to migrate the full stack to Python, Golang, or whatever. That’s why there’s all that COBOL code running in banks and stuff. It works no one wants to risk touching it.
In more data science-y terms, we’re all living within a giant optimization problem and running hill-climbing algorithms and our efforts are always homing in on local maxima that might trap us.
So how does path dependency relate to making new product?
Since I constantly take a historical view upon events and tech, I obviously think a lot about this as I work. Specifically, the evolution of a product is a path with many decisions where it’s not clear what the optimal choice is for any given decision. Choosing to do SOMETHING despite the uncertainty is what makes the job of the product manager/product lead so difficult, and my job as a Data Scientist/Analyst/UX Researcher is to provide information to help make those choices just a tiny bit more rational.
We’re all just blindly fumbling our way into the future making vaguely-rational choices based on limited information and guesses. That’s fine, because that’s how these things work. The problem is when success comes and the path taken slowly petrifies into lore and dogma.
We need to recognize that we’re forever embedded within a given path in the arc of history because there will be times when we do get stuck at a local maxima and we need to discover a way out.
These local maxima manifests in very curious ways. Very often, it becomes a blind spot, an unconscious sacred cow that even people who know to question sacred cows might not see.
One interesting example
One interesting example of this behavior is when people develop tunnel-vision around a certain problem because it’s the most recent design decision being made.
One time at work, we had introduced a new expensive feature to a product. Then, perhaps because it’s an expensive feature, sales were not as high as management expects and a bunch of meetings were called to figure out what that is. Is it the signup flow? Is it bad marketing? Are people not understanding the feature? Et cetera.
Obviously, being on the UX team for that feature, I was pulled into some of those conversations, looking into the various funnels for friction points that we could improve the situation as best we can.
After doing a bunch of analysis, the answers were pretty clear: there are 2 high friction points for that product. First, there’s a critical ‘request an increase in resource quota to be able to purchase the feature’ step which requires permissions and interacting with a support process. Second, the feature costs a huge amount of money to start up, 5 figures to start.
Now, the quota request aspect was inserted into the flow because there’s lots of concerns about stock-outs. There’s a finite amount of hardware to go around, and you can’t let random users request 5-figures worth of equipment capacity for instant provisioning willy-nilly. You’re setting yourself up for embarrassment that way because no one keeps endless racks of servers on hot standby for customers that might never appear. Capacity planning is a very carefully organized art. So it makes sense to put this in when you’re not sure how much demand exists.
So, if you’re building a product that is facing lower-than-expected sales, which do you think is the bigger barrier to getting sales? A requirement that a user clicks a form and requests quota from customer support, or a “pay $10k button”?
From a pure UX perspective, ignoring all back-end engineering constraints, the cost is most likely the problem, not the added friction of a quota request. After all, if you’re prepared and authorized to spend $10k, 20k, 50k on a product, a quota request that interacts with a support person isn’t really going to stop you. Meanwhile, there’s all sorts of authorizations and bureaucracy needed to get authorized to spend so much in most companies I’ve worked in.
But the entire product team discussion revolved around understanding and fixing the signup form, which ultimately meant trying to improve the quota experience. There wasn’t anything of note left to change. The concept of “we must have a quota” had become so baked into the product design that it was becoming a blind. If only that friction could be reduced, sales would go up to where they should be.
This is an example of being hemmed in by path dependency in product design. A previous decision “we must have quotas to prevent too many people overloading the system” that made sense at the time (and still makes some sense in the present), later winds up creating a central problem with no clear solution.
In perfect world where things were rebuilt from scratch with present knowledge, the quota requirement might be completely removed or modified to only apply in situations where there might be a risk of stock-out because the price-tag alone serves as a speed-bump. Given existing adoption rates, it might be a feasible solution.
Even if it such a design couldn’t be a permanent solution (imagine if word spread and sales grow exponentially), merely testing such a design would settle the question of whether the quota form is affecting sales or not very decisively. Once that issue is settled, we can move on to solving the more important issue of understanding why people who should want the product, have the money, but aren’t buying it.
I should reiterate that the baked-in requirement for quota wasn’t ENTIRELY just an overlooked assumption. There are very legitimate engineering reasons why it needs to be in place. What I’m pointing out is that the assumption wasn’t questions and examined closely because it should be possible to design a new product that reduces or eliminates the quota in some situations.
Knowing past decisions helped here
Challenging assumptions is old hat. It’s a well-known tactic for getting out of a rut. It’s why some teams actively encourage bringing in new people with fresh views because those newcomers don’t come with the historic baggage and can spot overlooked assumptions.
The problem has always been identifying assumptions to knock out. Luckily in this case there were very few things in play, so anyone would stumble upon it by process of elimination. But I’ve been on bigger, more complicated products that have hit the exact same situation before and trial and error isn’t a viable option.
Complex products are the result of a long chain of complex decisions, each baking in more and more assumptions that could potentially be challenged. Identifying them is very challenging, especially if you don’t know what decisions have been made!
Thus, history is important, or at least, time-saving.
Eclipse micro-follow-up
So the prediction problem is pretty fascinatingly tricky when trying to do it within a vacuum.
The orange line below is the days between lunar eclipses from an omniscient point of view that can see all eclipses (including penumbral eclipses) from anywhere on the globe. Note how amazingly regular it is!
The blue line is when you can only view from NYC, and assuming human eyes can’t (or may miss) penumbral eclipses. The gaps are MUCH more unstable, despite it covering a period of a thousand YEARS of calculated observations. Even visually there’s very little pattern to it for my human brain to latch onto.
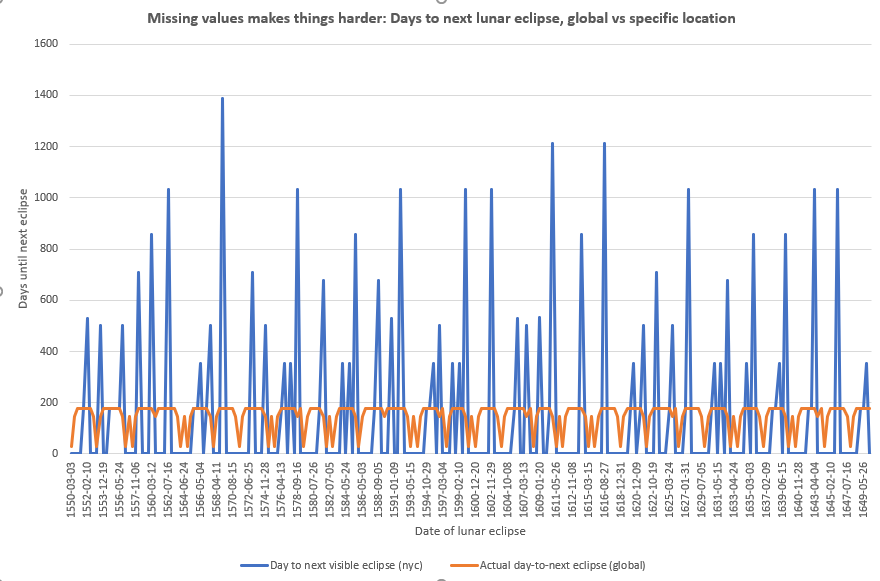
I think it’s becoming clear that without having some extra information to the data set, it might be impossible to predict eclipses as is. I SUSPECT that if we included the dates of all the full moons (since all eclipses must happen during a full moon) it’ll simplify the problem even further and make predictability much easier.
Adding full moon data should simplify the problem EVEN MORE by reducing the problem into “will the next full moon be an eclipse?”. It should pre-bake in certain cyclical information that doesn’t pre-exist in the data set.
Skyfield has a lunar phase function so calculating those should be easy.
But I still haven’t tried to actually do anything with the dataset as of yet, so who knows if this works. If you try it, let me know how it goes, it’s surprisingly fun to take a break from… *gestures all around*.
About this newsletter
I’m Randy Au, currently a quantitative UX researcher, former data analyst, and general-purpose data and tech nerd. The Counting Stuff newsletter is a weekly data/tech blog about the less-than-sexy aspects about data science, UX research and tech. With occasional excursions into other fun topics.
Comments and questions are always welcome, they often give me inspiration for new posts. Tweet me. Always feel free to share these free newsletter posts with others.
All photos/drawings used are taken/created by Randy unless otherwise noted.
Maybe you were distracted this week but this was a great read. You put into words everyday problems that are often not discussed. Data Scientists often get lost in the algorithm and forget most value is gained with the interaction with other areas.
Your story about tunnel vision reminded me of the book Black Box Thinking by Matthew Syed on how we as expert can get to focused on a problem and ignore more obvious issues. Keep it up!