


Practicing data prep with Wikipedia data
It's fairly realistic, albeit messy, which is the point


An utterly badass alpaca at the Queen’s Zoo this autumn
Long ago in the darker ages of the past, finding data sets to analyze was difficult. Back in the early 2000s, the most common place to get ANY data at all would be from the government. The US Census, various government statistics, financial reports, that sort of stuff. Storage was expensive and bandwidth was super scarce.
So in the past decade, with the explosion of cheap storage, plentiful bandwidth, open science, and data science being in the public consciousness, more and more public datasets have been released. For people who are interested in data science, but aren’t in a position to actively practice on real data, it's never been easier to find publicly available data to use for practice, Google has even released a dataset search tool.
But everyone who tries to learn data science using such data sets must remember that even these public data sets are not quite equivalent to “the real thing” that we face in production.
Cue jokes about the Iris data set here.
Very often, public datasets are unnaturally clean. They’ve been documented, anonymized, and normalized in order make the dataset easy to consume by complete strangers to the dataset. It’s great for when you want to use the data for a specific predefined purpose, like for learning to do data modeling, but it’s bad for learning how to clean, wrangle, and prepare good datasets to begin with.
Aside from being “too clean to learn about cleaning”, the other problem with public data is that they're most likely outside of whatever industry/domain you're planning on working with. It means so you can't bring (or learn) any specific domain knowledge to bear upon the problem. You’re literally that guy in the xkcd comic that is “here to help with algorithms”.
I’m not a climate change scientist, the amount of insight and anomaly detection I can personally bring to set of global temperature measurements is exactly zero. I’d have to rely on other experts.
So why practice data preparation?
I wrote about how data cleaning isn’t grunt work, Instead it’s critical work to understand your data. It’s not a popular topic for people to write about, meaning you more or less have to have hands-on experience to get a sense for it. Hence, it’s a good idea to practice it a bit.
The problem is that large sites don’t usually publish their web server logs for public inspection. It could lead to all sorts of privacy and security issues to have every HTTP request log entry out in open like that. Similarly, most places don’t just post internal analytics in the public. So I’ve always found it hard to recommend things for people to play with.
But then, there's Wikipedia
Recently Chris Albon had tweeted that much of Wikimedia’s (y’know, the people who run Wikipedia, among other things) data and analytics are publicly available on their analytics site. Since Wikipedia is one of the most visited sites on the internet, I'm most interested in seeing what they have for two reasons:
They have the volume that makes hand-analzying the data very difficult
The volume means all sorts of weird activity from all over the internet would be represented
Put those two factors together and it's almost guaranteed that the base data will not be clean enough to use in raw form. The main question is how much do they preprocess the data for us before making it public.
Obviously they must do a certain level of preprocessing just to conserve resources, stripping out verbose extra data, compressing logs and records down to save of storage and bandwidth. Generally these would be harmless operations that make things efficient at little to no information cost.
But on top of efficiency, they also have to protect user privacy. Imagine if full raw HTTP request logs of all of wikipedia were made public. Your IP and user agent would be associated with every Wikipedia page you've viewed… creepers, stalkers, advertisers, evil government entities, everyone would love to know that. So that must be filtered out.
So what do they have?
For the purpose of learning to prepare data, their more interesting stuff lives in the dumps.wikimedia.org section and the Analytics subsection within that.
Among other things, there are daily snapshots of how many pageviews on every Wikimedia property. There's a page that shows the definition of what a pageview actually is (because they make an effort to remove bot traffic from the counts).
Let's practice evaluating some data
Evaluating? We’re not going to clean and use?
Right now I just want to decide if I even want to use this data that's been provided. I'm not exactly sure what's in it and how usable it is in it's current state. We need to take a look at what's available and prove to ourselves that we can access it before deciding if we're going to use the data for anything at all.
These are the initial necessary transformations we need to play with this data anyways. Since we haven’t committed to using this data yet, I want to do the minimum viable analysis just to see if I want to spend the energy on a side project.
Pagecount data, first contact
Someone (also working at Wikimedia) helpfully suggested that to truly test our data cleaning skills, we should look at the older, legacy pagecount dataset. That got my attention. Working on a known-hard one is a good challenge and solid practice.
Here's a snapshot of the first few lines from 2016 (the final year of this data set):
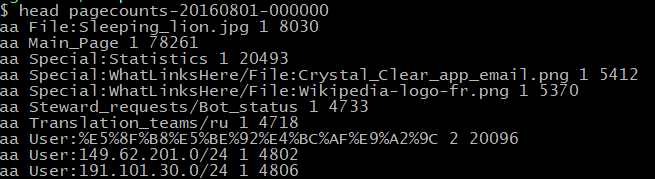
Within the first 8 lines there's a bunch of garbage-like characters in there. Someone familiar with web data will notice that it is percent encoded like in URLs. If you’re familiar with the mediawiki software, you’ll recognize those as pages.
Another glance seems to show that the file is delimited using space characters, 4 fields per line (hopefully). The first is some code, the second something that looks like a Wikipedia page, and two numbers. We need some documentation to fully understand what those mean.
The page linking to the dump mentions a few details about the pagecounts-raw data we are looking at.
The second column is the title of the page retrieved, the third column is the number of requests, and the fourth column is the size of the content returned.
These are hourly statistics, so in the line
en Main_Page 242332 4737756101
we see that the main page of the English language Wikipedia was requested over 240 thousand times during the specific hour. These are not unique visits.Also on the bottom of that description page it tells us that the data has been generated in various ways over the years. All this is typically more documentation than I'd expect from a corporate internal database so this feels pretty good.
Now we just need to see if we can load this data into a programming language according to the spec of 4 space-delimited columns. I'm always skeptical that similar processes will go smoothly, somewhere there must be an extra space or newline character waiting to trip me up. There doesn’t seem to be any quoting characters like in certain CSV dialects.
Since it’s space delimited, we can be lazy and just use the CSV module to quickly parse through the file. it takes slightly less typing than manually splitting the rows by space.
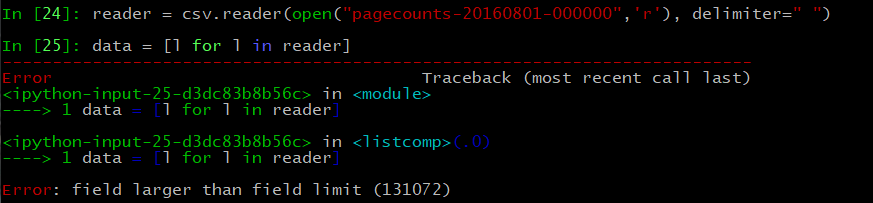
Annnnd something busted. CSV is complaining something was longer than the field limit set in the csv limit… we could just raise the limit, or just split the file manually to see what happens, I went the manual method.
In []: ifile = open("pagecounts-20160801-000000",'r')
In []: data = [x.split(" ") for x in ifile]
In []: len(data)
out[]: 6270942
In []: data[0]
Out[]: ['aa', 'File:Sleeping_lion.jpg', '1', '8030\n']
In []: [x for x in data if len(x) !=4]
Out[]: []Apparently every line in the file has 4 fields, no lines with fewer or more. Good to know that things are at least consistent in this file.
Now let’s deal with those pesky % encoded strings. It’s likely url encoding so we’ll just decode that to see.

Python3 also has much better native Unicode support than Python2, where we probably had to mess with string decode/encode stuff to handle this. It’s nice that it has no trouble handling things.
In []: max([len(x[1]) for x in data])
Out[]: 2042The longest field of the whole file seems to also be only 2042 characters long, which makes me wonder why the CSV module choked upon loading things… guess that field limit is fairly low. From here, let’s clean a bit more. To make life easy I’ll throw it into a dataframe since it’s getting annoying to apply code manually to individual columns.
In []: data2 = [[x[0],urllib.parse.unquote(x[1]),int(x[2]),int(x[3].strip()) ]for x in data]
In []: data[7]
Out[]: ['aa', 'User:%E5%8F%B8%E5%BE%92%E4%BC%AF%E9%A2%9C', '2', '20096\n']
In []: data2[7]
Out[]: ['aa', 'User:司徒伯颜', 2, 20096]
In []: import pandas as pd
In []: df = pd.DataFrame.from_records(data2)
df.describe()
In []: df.describe()
Out[]:
2 3
count 6.270942e+06 6.270942e+06
mean 3.677704e+00 8.671487e+04
std 2.267357e+03 5.014291e+07
min 1.000000e+00 0.000000e+00
25% 1.000000e+00 8.445000e+03
50% 1.000000e+00 1.284800e+04
75% 1.000000e+00 2.912600e+04
max 5.336925e+06 1.220446e+11
# It didn't describe columns 0 and 1, so describe them here
In []: df[0].describe()
Out[]:
count 6270942
unique 1156
top en
freq 2295523
Name: 0, dtype: object
In []: df[1].describe()
Out[]:
count 6270942
unique 5729694
top 2007
freq 153
Name: 1, dtype: object
Okay, that was dull, what now?
Right now, data from the most recent year, 2016 seems fairly well behaved. I actually picked fairly recent data (2016 is the last year of this dataset) specifically because I expect things to go relatively smoothly.
We could apparently clean the file up to a usable state in just a handful of lines of python. It looks like we have a functioning data file of approximate 6.3 million rows. But this is just a lone single hour of a day of data in 2016-08-01. To do anything interesting we’re going to need multiple days of data.
If we stopped here, this would be super anti-climatic. Analytics pipelines that are actively used and watched improve over time like wine. Neglected pipelines tend to rot away. In this case, rough pagecounts seems used by enough people that they’re likely to fix issues that come up, meaning the true “fun” is yet to come.
Against that backdrop, the most concerning thing about the data sits casually on the bottom of the documentation:
Up to 2015, the dataset has been produced by Webstatscollector.From 2015 onwards, the dataset is getting produced by stripping down extra-information from Pagecounts-all-sites.
Remember we had just checked a file from 2016, which came from Pagecounts-all-sites. Different systems means different shenanigans. We’re also need to back in time, meaning we get to rediscover any bugs that have been fixed over time. So, let’s try a file from 2014, late in the life of the older system and see what happens.
$ head pagecounts-20140101-000000
AR %D9%86%D9%82%D8%A7%D8%B4_%D8%A7%D9%84%D9%85%D8%B3%D8%AA%D8%AE%D8%AF%D9%85:%D8%B9%D8%A8%D8%A7%D8%AF_%D8%AF%D9%8A%D8%B1%D8%A7%D9%86%D9%8A%D8%A9 1 230243
De %C3%84sthetik 3 194742
De Cholesterin 1 0
De Steroide 1 0
De Vippetangen 3 26119
En.d Throwback 2 6076Instantly we can see differences. First field has capital letters for the codes in the first column, the 2016 file only used lowercase. But a simple caps change, we can roll with it. Let’s shove it into python…
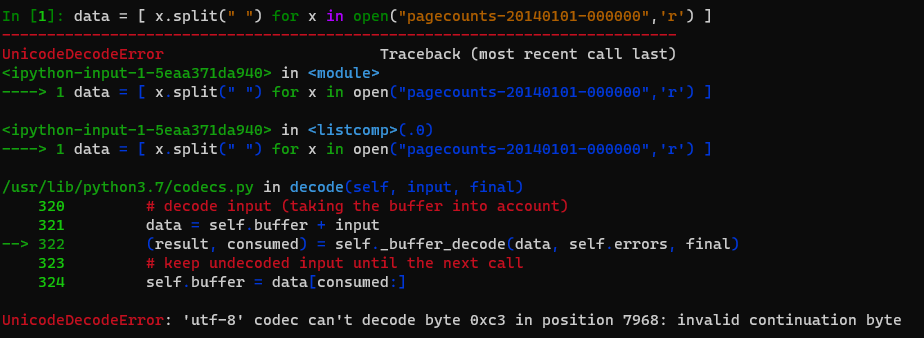
Um… Crap. What encoding is this file? Actually, what’s breaking this? Can we print it?
In []: data = []
In []: ifile = open("pagecounts-20140101-000000","r")
In []: for line in ifile:
...: try:
...: data.append(line.split(" "))
...: except:
...: print(line)
...:
---------------------------------------------------------------------UnicodeDecodeError Traceback (most recent call last)
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xc3 in position 7968: invalid continuation byte
In []: len(data)
Out[]: 66892Ok, so it breaks at line 66893… what’s there?

Pop it open in vim and it’s just a bunch of bytes… for the ar country code… Argentina? Am I in a Latin-1 file instead of UTF-8?!?! These are supposed to be the url-encoded page paths… RFC1738 specified that URLs should be ASCII, not ISO-8859-1.
BUT GUESS WHAT, it works. Most likely, some upstream processing read the ASCII, decoded the url encoding, then somehow accidentally re-encoded everything into ISO-8859-1. I should be thankful that the system didn’t seem to poison other languages somehow…

Once we get to this point, our old cleaning string
data2 = [[x[0],urllib.parse.unquote(x[1]),int(x[2]),int(x[3].strip()) ]for x in data] does execute, so theoretically this data set could be loaded into a database or something along with the 2016 file. But now we have new worries…
Joining the data files into a coherent data set
We already know that capitalization is different in column 1, we also should make sure that the values are similar between the two. It’s possible the codes have changed (though no documentation seems to indicate this thus far).
Still, this was just a file from 2014. The dataset goes all the way back to 2007, 7 years is a huge amount of potential tech changes. Here’s a quick look at the first few lines of the earliest 2007 files…
$ head -11 pagecounts-20071209-190000
aa Enqlizxsh_-_English 2 2
aa Main_Page 5 5
aa Special:Categories 1 1
aa Special:Contributions/M7 1 1
aa Special:Recentchangeslinked/ 1 1
aa Special:Whatlinkshere/ 1 1
aa Special:Whatlinkshere/Main_Page 1 1
aa User:PipepBot 1 1aa User:Ruud_Koot/Sandbox1 1 1
aa Wikipedia:General_disclaimer 1 1
ab %D0%90%D2%A7%D1%81%D1%83%D0%B0_%D0%B1%D1%8B%D0%B7%D1%88%D3%99%D0%B0 4 4Looks like capitals for the first column wasn’t in style yet because a grep ^a didn’t find any in that 2007 file.
So, assuming we want to use this dataset for its entire duration… we’d at the minimum need to do these things before we can start looking at the data from end to end:
Parse the filenames for date and time (also find out what time zone its using, it’s probably documented somewhere), add those date/times as columns in the data
Go through every file and check for times when capitalization exists in the first column or not, correct that. Or just brute force lowercase everything upon ingestion
Make sure codes and columns counts are consistent, that there’s no wonky newlines or spaces being introduced by bugs. We didn’t find any today but there could always be a nasty surprise
URLs are supposed to be case sensitive, but I need to verify that is the case for Wikimedia sites, their web servers may use case-insensitive URLs and that might affect our math
Make sure our ETL logic knows how to handle the possibility of freak character encoding issues, we’ve already seen ISO-8859-1 and UTF-8 show up with no warning, they could be others
Dump all this into a database for querying… unless it all winds up being too big to fit in a database and we need to move to a noSQL solution of some sort
Only when we manage to get this data into a consistent database format can we finally start looking for things wrong within the data points instead of things wrong about the data. We can answer questions like, how do outages affect the data, are there weird biases, is there anything wrong about how the data was collected that causes strange biases. Y’know, basic data quality issues.
What have we learned about the data?
Most importantly, that it very likely has formatting traps hiding inside of it that we simply haven’t stumbled upon yet. But besides that, what else have we learned?
First, we’ve started seeing glimpses of the back end infrastructure. These pageview counts are the result of some kind of processing pipeline that’s semi-opaque, for example here’s the description of the Webstatscollector job used until 2015. It obviously has been changed over the years because we saw weird bugs in processing pop up part through. That means ANYTHING could potentially have gone wrong with that pipeline over the years.
Second, we learned that the documentation to the data is… better than nothing, but obviously leaves implementation details out. We’re going to need to piece together what the backend looks like over time. These details will be important as we get this data loaded and finally start looking for data inconsistences.
Since I’ve been told that this pagecount dataset is evil up front. I’m sure that there are even more crazy surprises lurking within. I just haven’t hit upon them with my super quick scanning of 3 sampled files in a 9 year long data set.
And this work is somewhat throwaway
Even though we’d have to spend effort to make sense of Pagecount data generated since 2006-2015, the data and the systems that power it have been retired in favor of Pageview data. That means there’s an entirely different system, with different properties to understand.
Somehow this article has gotten surprisingly long, so let’s call it a night here!
About this newsletter
I’m Randy Au, currently a quantitative UX researcher, former data analyst, and general-purpose data and tech nerd. The Counting Stuff newsletter is a weekly data/tech blog about the less-than-sexy aspects about data science, UX research and tech. With occasional excursions into other fun topics.
Comments and questions are always welcome, they often give me inspiration for new posts. Tweet me. Always feel free to share these free newsletter posts with others.
All photos/drawings used are taken/created by Randy unless otherwise noted.