

The best parts of data science isn't even the tech
The best parts of data science isn't even the tech
The Human Experience

I promised myself I wouldn’t write about the election, because O.M.F.G. it is just too much. HOWEVER. I did see something election related that tickled a muse awake, so I’ll come extremely close to writing about the election, but veer off quickly onto data work.

I’m starting writing this deep into Thursday night, November 5th, when a ton of people on my twitter feed and across the US are watching vote counts trickle in from critical states of Georgia and Pennsylvania. It’s already 2 days after the election and we still don’t know who the next President will be due to how ridiculously (and depressingly) close it is.
Right now, a lot of people at least in my data twitter bubble are obsessed with this site here: https://alex.github.io/nyt-2020-election-scraper/battleground-state-changes.html. I’ve screenshotted it below because by the time this post publishes on Tuesday things will have definitely changed.
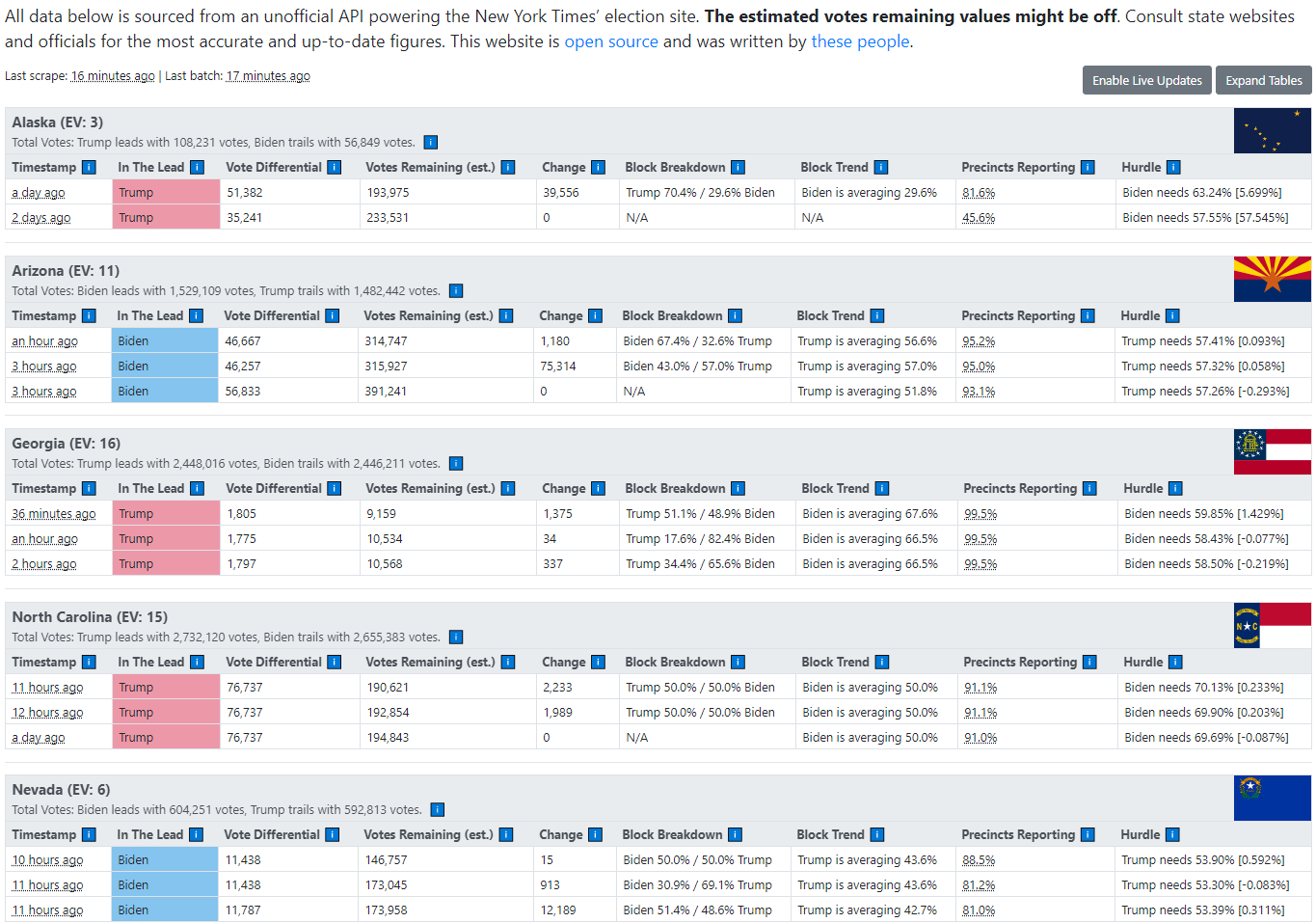
It’s a very simple site that is open source. It pretty much pulls JSON from the New York Times on a regular basis, and then archives and versions the JSON so that deltas could be calculated. This is allowing people who are frantically refreshing the page to see when new ballot result chunks are updated, as well as seeing who’s in the lead and whether the races are trending closer or further apart.
It’s literally a big table that does basic arithmetic on scraped JSON data, formatted very well to maximize utility. As Sean puts it in this tweet, this is not a very complicated setup, but it is gripping the attention of a LOT of people.

I looked at this and saw a wonderful example of data science/analysis. In terms of data science projects, it’s a super simple thing to create — scrape data, record changes, do basic math, display to stakeholders. It’s claim to greatness is because stakeholders, all the hundreds, thousands, of people who desperately want to know what is happening with this important election, feel that they’re getting what they need from it. It’s doing that one job so well that it’s gone viral.
This is legitimately more success than any data science project I’ve ever worked on personally. And this thing doesn't even generate any revenue to get excited about.
As I marveled at the simplicity of the whole site, I remembered that a few days ago, Vicki had posted a screenshot from Reddit’s r/datascience, the go-to place for depressing takes on data science:


It’s yet another thread about a disillusioned person who switched into a data science job thinking they’d be working on sexy technical problems, and resenting that they’ve spent 3 years being a “data lackey” doing SQL and regression and only accumulating domain knowledge they don’t care about. It’s a theme that pops up on a fairly regular basis on that subreddit.
Part of the problem is that the whole Data Science job has been over-hyped the past 5 years and leaves a lot of people with unrealistic expectations about how we’re all creating important machine learning models and helping build the future apocalyptic killer AI or something. People see cool things like self-driving cars, computer vision, and the promise of big paychecks.
Obviously, reality is far from that weird caricature, and a lot of people aren’t exposed to the truth before they go down this path. We’re going to continue facing an uphill battle with this situation until the hype eventually dies down. It can’t continue forever.
But I’m not here to talk about disappointment and disillusionment today.
After seeing that election dashboard, I couldn’t help but think of that anonymous person in the tweet. This vote counting dashboard is a super successful crystallization of practically everything that person dislikes about their data science work. There's practically zero technical challenge, there's honestly not even a statistical or mathematical challenge. It's simply doing a very good job of fulfilling an urgent user need. It will also be completely irrelevant and thrown away once the election is called and the winners announced.
We're all humans doing very human things for human reasons in service to ourselves and/or other humans. It’s humans all the way down. Most of the ultimate judgement for whether something mattered or not depends on how it affects other people in the world. Only a tiny fraction of data science is tech for tech's sake, and much of that is done in academia and blue sky basic research institutions.
This boring table of a dashboard (it doesn’t even have graphs!) was being refreshed by tons of people on repeat for a whole day. People were excited and sharing how many new votes ticked in and how it affects the vote difference. I never seen such a diverse and huge population on the internet be so excited at looking at a table of barely-formatted numbers.
Similarly, people were obsessed with vote trendlines, a statistical method practically as old as dirt. The reason was because it gave them a slight hope and something to be excited about. Such charts could easily be created in Excel, or manually estimated…



Utility and narrative made these go viral
Virality is a weird measure of success in many ways, but in this instance the amount of massive attention itself is attention-grabbing. The fact that these two normally boring things caused enough emotions in large numbers of people to spread speaks to how powerful they were.
Sure, they told people what they wanted to know, it’s confirmation-bias fuel. They gave the first flicker of hope after 2 whole election nights of dread and disappointment, and people responded. They were also simple enough to understand that everyone could use them without any training, or even documentation.
Most importantly, it let people understand the critical question of “how close are we to the goal? Are we getting closer?” for themselves. The audience had the model in their heads. They knew “the last batches of votes counted are from the mailed absentee ballots, those have a certain party bias to them, so we can estimate how much each chunk can shrink or grow the gap in votes” already. Since that hard narrative work has already been done, the charts and tables had the much simpler job of displaying the numbers clearly.
True impact is measured by the mark it leaves on the world, not the tool used to make it
Since data science has a big tech component, many practitioners and students either come from tech and engineering, or have strong interest in tech. Many of the first data scientists had learned a lot of the tech or math side out of their own interests and found applications for it. That background tends to create a bias for loving new technology.
By itself, that temptation isn’t bad and everyone gives into it on occasion, myself included. Learning stuff is often fun. It becomes a problem when tech starts to dominate and get held up as the most important thing, because it isn’t. Once you lose sight of WHY we’re doing the work we do, you can get stuck chasing mirages.
In photography, it's sometimes called “Gear Acquisition Syndrome”, GAS, because many photographers wind up obsessing over buying gear to “improve” their photography when the actual way to take better photos is the much more difficult task of learning to make the most of their existing gear with technique. It’s easier to spend tens of thousands of dollars on equipment than to do the hard work of carefully thinking about how you take photos and working on artistic vision.
It’s important to remember that when results appear in the world, the self-driving car, the viral chart, the anti-fraud system that catches the thief, the tool is almost incidental to the effect that matters to the world at large. When zoomed out to the level of “end user”, all those details are quickly ignored. Just like how there are a thousands upon thousands of patents for different ways to make cars go, but the majority of people on the planet only care about fulfilling the need to get where they're going.
That's why at the end of the day, we need to always remember that the work we do in data science will always be experienced by the general population through the final output. Those end users only care about whatever job they need to accomplish, If it means using a JSON pipeline, or a color-formatted PDF, or network of Excel macros, so be it. They’re as able to see elegance in a data science pipeline as I am able to see elegance in quantum physics equations.
Only our data science peers will appreciate, or even care, about the “how". This is why we need to build up stronger professional networks and community. They're the ones who share the cringe and horror with you. Community is how we grow and learn as data scientists.
But community won't usually pay a salary or give us a million recurring users. There aren’t that many of us in the world, and never will be.
So it’s important to know what context you’re working under. Are you showing things to the community? Or are you making stuff for the world at large, which includes your non-DS stakeholders?
About this newsletter
I’m Randy Au, currently a quantitative UX researcher, former data analyst, and general-purpose data and tech nerd. The Counting Stuff newsletter is a weekly data/tech blog about the less-than-sexy aspects about data science, UX research and tech. With occasional excursions into other fun topics.
Comments and questions are always welcome, they often give me inspiration for new posts. Tweet me. Always feel free to share these free newsletter posts with others.
All photos/drawings used are taken/created by Randy unless otherwise noted.
Thank you for the post Randy! On a different note from Samid, this is super encouraging as a newcomer with a passion for story telling that is building the math and tech skills from scratch.
Excellent post! So many newcomers (and not so new) want to shine using the algorithm than won the latest competition that they forget the how their results will be used.