

The delicate art of making ourselves wrong
The delicate art of making ourselves wrong
Modeling for incorrectness

This week’s post was inspired by some readers and folk on twitter asking some questions in response to me soliciting ideas/questions, though the specific discussion was unrelated and just made me think of the topic.

In 2020, very early on in the pandemic, I distinctly remember seeing a number of tweets/infographics that I’m having trouble finding again due to all the keywords being taken up by the ongoing mess of what I’m going to collectively call “pro-COVID advocates”.
As a reminder, this was very early in the pandemic where information was pretty scarce, but policymakers needed to make decisions about what response their country would be taking. In hindsight we would learn which of those decisions worked or not, but I’m not here to talk about COVID-19 today. I’m talking about modeling.
The graphics I’m failing to find to was discussing the projected first wave of infections, hospitalizations, deaths, and how interventions like social distancing was supposed the toll the disease would inflict.

The discussion highlights up a dilemma that people who use models to predict the future, in order to change the future, have to deal with. If you predict one future, then take a costly action to avoid said prediction so that it doesn’t come to pass, there will always been a question of, was the cost necessary? Did we overpay? What if our prediction was bad and our current future was actually the natural one?
In an ideal world of magic wand-waving experimental designs, you’d solve this issue using a randomized experiment — A/B test the two situations and now you can measure differences and see if the cost was worth it. Obviously, this cannot work in all situations. While there are definitely moral and ethical reasons for why you can’t split test a pandemic response, there’s also the very practical issues of it being extremely difficult to find sufficiently equivalent participants on both sides of such an experiment.
Now, obviously, this is not news to a bunch of fields like economics, public health, and other public policy related fields. They instead often have to rely on quasi-experimental designs and lots of ingenuity to try to tease apart experimental effects from other sources of noise. If you come from any of those fields, you’re probably rolling your eyes at me right now.
The current situation of all 7+ billion people on the planet being forced to participate (one way or another) in a giant quasi-experiment highlights how confused and messy this whole situation is. In the future, when this pandemic eventually passes, we’ll get to experience this for generations to come as climate change continues to progress.
So what about us folk in industry?
If you’re anything like me, just a cog working in industry, all these extremely important models that have literal implications on life and death seem like an alien planet. None of my typical decisions at work will affect ever lives to such a degree. But despite that fact, we data scientists still need to deal with very similar situations occasionally. More importantly, we need to put some thought into how we handle such situations.
Where do these situations come up? In my experience, the most common situation this type of analysis is done revolves around planning and budgeting for the near/medium future. Given a huge stack of business assumptions and historical data, we build out a model of how much money we think we’ll have in the future. Then, after much discussion, a bunch of decisions are made by the executive team. How many people will we hire in the next year? Where will we try to expand? Where will we try to cut costs and by how much? In less positive times, these analyses can tell you how many people need to be let go, how many months are left before everything needs to shut down.
Then, once those decisions are made, at some point in the future those predictions and outcomes are compared against the past predictions. Did we hit our goals? How much did we go over, or under? What (if anything) went wrong? Can we do better?
As you can hopefully see, this pattern of decision-making — predict, intervene, evaluate — is exactly the same, just with lower stakes.
First up — Prediction
I always view these “what-if” modeling problems as a kind of system that you can zoom in and out of, and the most important part about getting these models “right” for purpose is to figure out the ideal level to zoom to.
In my experience, most systems can be modeled quite simply, and to a surprising amount of accuracy, if you’re willing to zoom way out and ignore all the internal details of the system. For example, if you carefully plot carbon dioxide levels against historic temperatures, you can find a strong correlation. From there, you can ride the correlation pretty hard to get a reasonable prediction of future conditions.
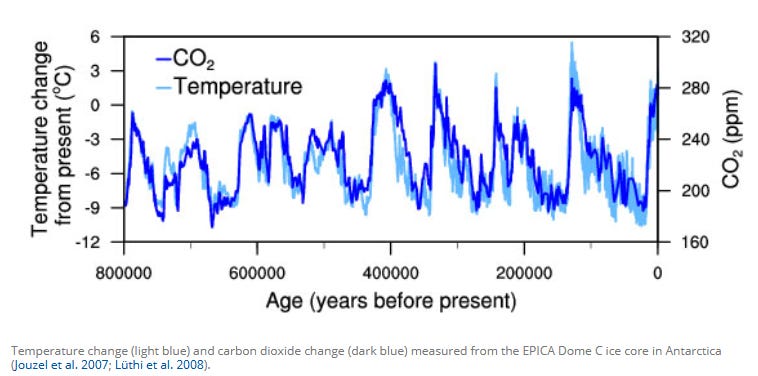
The problem with such a high level zoom-out is it limits your ability to do what-if analysis. All you have is a single CO2 parameter to play with to derive a temperature. All the internal mechanisms of how CO2 can change, how it affects the Earth to ultimately result in temperature change, and a million other details are glossed over.
The positive side of this is that you don’t accumulate any modeling errors for all the things you didn’t bother to model, hence you get the high starting accuracy. The negative side is that you have a correlation, but no real way of understanding to what extent the correlation will hold if things go off the charts. It also doesn’t give you much insight into exactly what effect any particular action you make will have on the system.
So to answer all those questions about possible futures, you need to zoom in and model more detail. To understand how the world is heating up, you’d have to start accounting for the heat energy coming into, and leaving the Earth overall (Energy balance models), then to explain why there’s lags in the CO2/temperature correlations you have to start looking at where all that heat could be stored, like in the oceans. The list goes on and on and on because the Earth is a really huge and complicated set of nested systems. The IPCC published an extensive evaluation on climate models in 2018 and the list of different models and things they look at is massive.
Luckily, our simplistic industry models will never analyze systems of such complexity, nor require so much rigor. Instead, we just need to be aware that every time we zoom in a bit, add in a new component to the model, it increases the risk that we’re introducing an unintended bias, either a tendency to overestimate or underestimate, into the whole model. It’s very common to start with a rough model that’s accurate to within maybe 10%, and then it becomes to within 15% when you “upgrade” to a more detailed a model. Then you need to spend a few weeks working the kinks out.
Next — Intervene
Once you have a model zoomed to the right level of detail, meaning it exposes a bunch of “levers” that you can theoretically make changes to, we can move on to (thinking about) making interventions. While the previous step of “modeling out what’s going on” could have been a huge amount of research and work, things get much more interesting here.
We get to make stuff up!
Specifically, we get to make up scenarios that change our model’s parameters to see what the result is. What happens if we add 50% new sales over the course of the year by hiring 10 people? Can 10 people even boost sales that much? What happens if we shut down in July and took the whole month off?
The whole point is that if we have a strong belief in the accuracy of our model to handle these new inputs, we should be able to explore our options now. The key difference between these what-if assumptions and the model assumptions is they’re generally not as well vetted. There’s no guaranteed we can boost production by 5%, just a hunch and belief that we can find that much improvement next year.
The interesting part about all this now we get to debate our model assumptions. All the modeling work up until now, you’ve had to make various reasonable assumptions and simplifications just to get the damn thing to work and come out fairly accurately. Now that you’re attempting to project into the future, you need to justify those assumptions, as well as the assumptions of the hypothetical scenarios. If you don’t have an understanding of those assumptions, you’re more likely to cause the model to fail. If you assumed all cows are spheres falling through a vacuum, your model will have trouble predicting moving cubic cows in the ocean.
There’s a bit of an art to playing with these models. You want to stay “within reason” for parameters, to avoid accidentally break the model, but “reason” is ill defined. Some people will be more aggressive/optimistic, others will be the reverse. After you play with a bunch of these scenarios, a final decision is made and things start happening in the real world.
Finally — Evaluate
After doing all this work, then doing actual implementation of your decision, you’ll finally need to answer the question “did we succeed”, and possibly, “where did we go wrong?”
This is the part where we’re trying to prove ourselves wrong. In the sense that, if our models are working correctly, whatever what-if scenario we chose to implement should have come true, and we should have avoided the original predicted future. Often you’ll see this expressed as a “baseline scenario vs current scenario”, much like the budget baseline projections put out by the Congressional Budget Office which are used to compare proposed federal government budgets against existing budget projections.
What I find very fascinating, and somewhat terrifying, about this whole process is the status of model truth very often shifts. Whereas originally we go into big discussions about assumptions and model methodology to assure ourselves that our what-if analyses aren’t just crazy talk, when it comes time to do the post-hoc evaluation, we very often take the original baseline model projects as “truth”, with very little thought going into the details of the old model, despite it also being a model and subject to errors.
I suspect the line of reasoning for this ready acceptance of the baseline is because, “it’s the baseline, it wouldn’t have become the baseline if we hadn’t vetted it to the best of our ability”. So the baseline model, flaws and all, represents a kind of state of the art.
But, is it? Really? That doesn’t seem true for my work.
This is what keeps me up with the whole line of reasoning. But at the same time, it’s really hard to justify putting in even more time to poke and tweak the model when there’s a giant pile of work left to do to compare current reality against what we thought was going to happen back when decisions were being made.
The other unsettling thing is that when things have deviated from the model, you’re going to take it apart and compare the pieces in an effort to try to figure out what went wrong. Did we fail to hit sales targets because marketing didn’t get their 20% boost? Or was it because of that big outage we had during our biggest season of the year? Now we’re neck deep debating fiddly details about sub-models which miiiiiiight not be uniformly as rigorous.
By the time we get to this point, I feel like we’re increasingly approaching shaky footing. Where’s the reference point that we define our baseline model’s “wrongness”? This is an issue that I’ve been oblivious to for much of my career, despite executing these sorts of analyses all the time. I don’t really see a clear answer to it.
About this newsletter
I’m Randy Au, currently a Quantitative UX researcher, former data analyst, and general-purpose data and tech nerd. The Counting Stuff newsletter is a weekly data/tech blog about the less-than-sexy aspects about data science, UX research and tech. With occasional excursions into other fun topics.
All photos/drawings used are taken/created by Randy unless otherwise noted.
Supporting this newsletter:
This newsletter is free, share it with your friends without guilt! But if you like the content and want to send some love, here’s some options:
Tweet me - Comments and questions are always welcome, they often inspire new posts
A small one-time donation at Ko-fi - Thanks to the folks who occasionally send a donation! I see the comments and read each one. I haven’t figured out a polite way of responding yet because distributed systems are hard. But it’s very appreciated!!!