

The User-Agent — That Crazy String Underpinning a Bunch of Analytics
The User-Agent — That Crazy String Underpinning a Bunch of Analytics
It’s surprising to think we rely on this as much as we do

It’s surprising to think we rely on this as much as we do
Only Innocent Browsers Here (Photo: Randy Au)
Work in web analytics for any amount of time, even less than a week I’d bet, and you’re going to hear about this thing called the “User-Agent”. It’s this string that we get from users, and it’s supposed to tell us various things about them. If we’re supposed to be using this thing to count and analyze users somehow, we need to understand it some more.
Currently in 2019, the most important use for it is figuring out what device (desktop, phone, etc) a client is using for the purposes of sending the correct page design to the client. It’s not the only way someone can do device detection, but it forms a very important foundation. Even Javascript device detection libraries often just request and parse the User-Agent.
User-Agents also provides one of the data points for fingerprinting users without the use of cookies. It’s included with every HTTP request and can potentially be very long and unique to a user in certain uncommon situations.
But what IS this string all about, and why is it sorta crazy any of this works?
So what’s a User-Agent string?
The User-Agent (UA) is a field in the HTTP header that the client “should” (in the technical RFC 2219 sense where they may be technical ramifications if it is not done), include the field with a request to a server. This is codified within both RFC 1945-HTTP/1.0 and the current RFC 7231-HTTP/1.1 specifications (see the images below for the specific sections). RFC 7540-HTTP/2 is concerned w/ the HTTP message itself and not the headers where UA lives, so 7231 applies there too.
Let’s take a look at how the UA was defined in the RFCs.
The TL;DR is as follows: User-agents are…
A field in the HTTP request header
That SHOULD be included in every request
Should be in US-ASCII (as with the whole header)
Consists of a series of “product tokens” — a product name string with an optional version number, separated by a “/”
Product tokens are separated from one another by a space.
Comments are allowed by enclosing them in parentheses
Product tokens should be ordered most important first
One product should not copy another product’s token to declare compatibility
No advertising, no overly fine-grained detail
RFC 1945 — HTTP/1.0 from May 1996
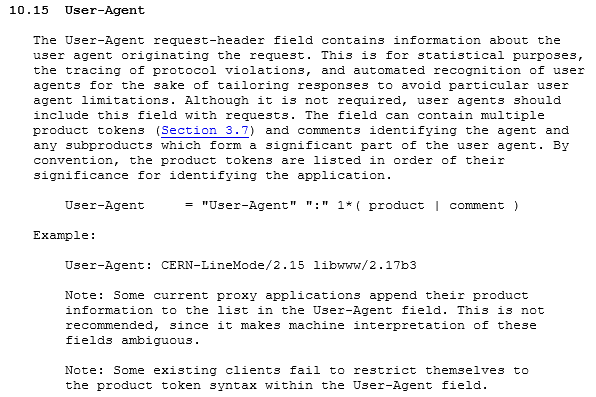
rfc1945 — https://tools.ietf.org/html/rfc1945 — HTTP 1.0
Although it is not required, user agents should include this field with requests. — RFC 1945
RFC 1945 predates the RFC 2119 language of SHOULD, so it reads more casually. Still, the most important points are these:
Not required but UA should be included with requests
Used for statistical purposes, tracing protocol violations tailoring responses to user agent limitations
Field can contain multiple “product tokens” and comments
Product tokens are listed in order of significance for identifying the application
It’s interesting to note that, even in this RFC, it already warns of anomalies like some proxies will append data to the UA which makes interpretation ambiguous, and some clients don’t follow the product token syntax.
What’s a product token?
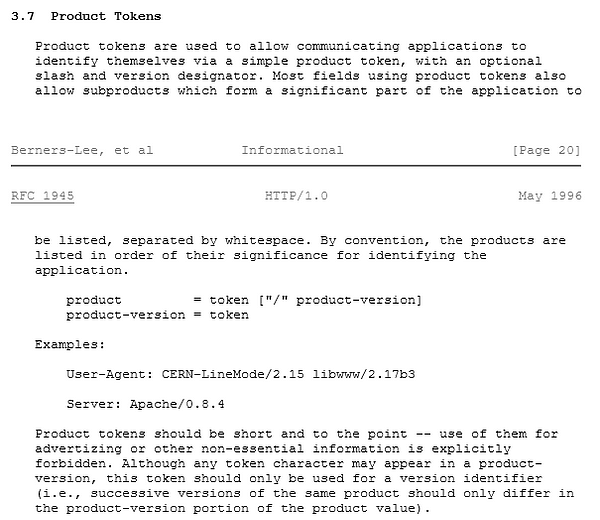
RFC 1945 — HTTP/1.0
A product token is simply in the format of product/version where version is optional. Tokens are whitespace delimited, so products shouldn’t have whitespace. Historically, ISO 8859–1 (Latin-1) and RFC 2047 (Base64 and Quote-printable) encodings were allowed. Nowadays, the spec says to use US-ASCII and any octet > 127 is treated as “opaque data.”
So, in theory, you could shove emoji or a base64 essay into the UA, but all bets are off on how the server decides if and how to handle it.

Encoding to be used in HTTP header fields — RFC 7230 https://tools.ietf.org/html/rfc7230#section-3.2.4
RFC 7231-HTTP/1.1 from June 2014 (current standard)

rfc 7231 https://tools.ietf.org/html/rfc7231 — HTTP 1.1
Subsequent versions of the HTTP RFCs have more standardized language, but generally, things remain the same. It’s still product/version entries separated by spaces, with comments in parentheses. What’s notable is the addition of very specific prohibitions against putting non-essential, fine-grained information or advertising in the UA. Overly long UAs are specifically stated to potentially fingerprint users (we’ll get to this later).
It’s also specifically stated that it’s discouraged for products to use the product tokens of other products to declare compatibility. We’ll get into that next.
What’s interesting about all these additions is that they didn’t exist in RFC 2068 the original HTTP/1.1 spec from January 1997,or RFC 2616 dating from June 1999. In the intervening 5 years of exploding internet use, it seems they had seen some abuses that they wanted to stop.
Historic User-Agent Use
While knowing what the RFCs say about User-Agent strings is useful to know the format that things take, it doesn’t tell you very much about how it is used in practice.
As stated quite amusingly here in a “History of the browser user-agent string”, the reality of UAs today is that practically everything pretends to be Mozilla first. This was because back in the ‘90s when browser features were rapidly changing, the Mozilla browser had certain features like frames that were initially unavailable in competing browsers, so web designers sent different versions of the page based on the User-Agent.
But as the other browsers caught to Mozilla in terms of features, web designers were slow (or didn’t bother) to update their serving rules to match. So browsers that could support advanced features were not served pages with such features. To get around this, the other browsers just declared themselves to be Mozilla to fetch the Mozilla version.
Soon, practically every mainstream browser just decided to declare they were Mozilla as the first product string, while adding the actual browser in a comment or a subsequent product string. This is most likely what prompted the latest RFCs to specifically say using another product’s string (i.e. Mozilla) is discouraged. Browsers still do it to this day, with no real signs of changing.
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.87 Safari/537.36-- A Chrome User-AgentMozilla/5.0 (Windows NT 10.0; Win64; x64; rv:70.0) Gecko/20100101 Firefox/70.0-- A Firefox User-AgentMozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362-- A Microsoft Edge User-AgentMozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko-- An Internet Explorer 11 User-Agent"Links (2.16; FreeBSD 12.0-RELEASE-p10 amd64; LLVM/Clang 6.0.1; text)"-- A Links2 User-AgentIf you’d like, you can browse the vast array of User Agents online with resources such as this one.
What you’ll also notice is that every browser is fairly idiosyncratic with the sequence and types of product tokens it has. With enough study you can fairly reliably know what device and browser a request is coming from. IE11 uses the comment Trident/7.0 to denote its render engine and “rv:11.0” to denote the IE version, Chrome (and Edge which switched to being chromium on the back end) are full product-version tokens, but will also claim Safari compatibility because they both use AppleWebKit. It’s a tangled web.
And what about robots?
It varies: some are more well behaved than others. Some state the bot as the top level product, some also claim Mozilla compatibility, or claim to be on a mobile device. Some are libraries that provide a default User-Agent that a dev can override but forgot to.
W3C_Validator/1.3 http://validator.w3.org/services - W3c's validatorGooglebot/2.1 (+http://www.google.com/bot.html) - A GooglebotMozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.96 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) - A Googlebot, but AndroidMozilla/5.0 (compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm) - one of the BingbotsPython/3.6 aiohttp/3.5.4 - Python's AIOHTTP librarypython-requests/2.20.1 - Python's Request libraryRobots and scripts are sooorta obvious, but you sometimes have to squint a little. They’re more likely to have URLs in the text (as part of a practice to allow people to identify and report misbehaving bots) but that’s no guarantee, you gotta parse it case by case.
Spoofing is Totally Allowed
For various reasons, whether for testing, compatibility, or privacy reasons, users may want to have their browser give a different User-Agent string than default. The RFCs specifically say that if a client sends a masqueraded UA, then it should be interpreted as the client intentionally wanting that version, even if it may not render correctly.
If a user agent masquerades as a different user agent, recipients can assume that the user intentionally desires to see responses tailored for that identified user agent, even if they might not work as well for the actual user agent being used. — RFC 7231, HTTP/1.1
Browsers often provide the functionality for users to spoof their UAs. That said, it’s extremely rare to encounter users who go through the trouble since the differences between browser functionality has largely become trivial from a user perspective.
OK, we know what UAs look like, how are they used?
One thing to remember about User-Agents is that it is a very old technology, and many of the things that it has been used for historically (such as basic analytics) have been given over to other technologies that can provide more detail and resolution.
Serving different versions of web sites
This usage is the original intended purpose of the UA string, giving the server the ability to serve different versions of the web page based on what the client is capable of handling. Internet Explorer 6 was perhaps the most egregious example of where site designers needed to know the browser version because of how poorly it handled modern web standards.
Fun side note, IE6 was a HUGE problem in the late 2000s/early 2010s due to its horrible standards support requiring lots of custom hacks from developers but stubbornly high usage numbers. The pain spawned efforts such as these to kill it.
Basic analytics
Back in the mid/early 2000s, UAs were an important tool in analyzing what users were using. Using Javascript to pull browser info was still in its infancy, so User-Agents were the most informative thing that you had. From this, you could see what percentage of your users were using IE6 versus Firefox (and whether you should stop using certain HTML features or not). You could also see how often the search engine crawlers visited, and whether you had actual human visitors or not. Primitive by modern standards, but better than nothing.
Bot detection
It’s considered good practice and manners for bots, web crawlers, and similar automated programs to identify to the server via the User-Agent string. Very often the UA will contain the string “bot” “crawler” “spider”, sometimes with a URL of the bot owner as a comment. But the specific implementation of the UA will vary wildly from bot to bot. This is because ultimately a human developer decides what “self-identification” means, there’s no standard format.
Basic bot control via robots.txt
The basic robots.txt file is used to tell what web crawlers and other robots should or should not access on a given web server. Very often, it doesn’t make a distinction between different types of clients, but there’s actually a facility to specify which User-Agent string is allowed in certain places.
Obviously, this assumes that the robot 1) reads and follows the directives in the robots.txt file and 2) identifies itself properly in the User-Agent (and again follows the directives).
Primitive User Fingerprinting
User-Agent strings can range from being very simple, to very long with many product tokens chained together. The most egregious ones would be browsers that had many sketchy toolbars installed, each toolbar would often append its own product token to the UA.
The longer the UA, the more likely it has strayed from the base default UA provided by the browser, and it becomes increasingly likely that the UA becomes unique to a specific installation. Working under this assumption, people could use UAs as a way to pseudo-identify a user across time and IP addresses. I’ve seen browsers with as many as 6 toolbars installed and that browser + IP combo was practically unique in the sea of requests, enough to track someone across the internet.
In practice, this method only really works on the tiny subset of people who have installed enough browser extensions or poorly spoofed their UA enough to stand out from the crowd of default strings. But even so, the UA still provides bits of entropy in a larger user fingerprinting framework that involves the use of Javascript and HTML5 methods.
I’ll have to get into device fingerprinting another day, it’s a huge topic. For now, if you’re interested you can take a look at this to get an idea of what is possible when you use the full range of tech possible, spanning request headers to Javascript, Flash, and HTML5 Canvas.
Device and Platform Detection
With many advanced browser features being detected directly via Javascript these days, this is probably the primary modern use of the UA string, figuring out what device/platform a client is running.
UAs found a new life in the late 2000s with the smartphone and tablet explosion. While UAs used to tell you what percent of your userbase was on IE, Firefox or Chrome on a Windows machine or Mac, we suddenly started seeing exciting new strings like iPad, iPhone, Android. Not everyone was using a desktop/laptop any more, but we could see what they were using and adapt!
These new devices had different physical screen sizes and physical capabilities. It wasn’t just “oh this browser has no Javascript/HTML5/CSS support” any more. This information is highly relevant to designers, especially on older early/mid-2010 devices that did not have full-HD 1080p or higher screen resolutions. (The iPhone 4S from 2011 had a 960×640 pixel screen.) Sites designed for mobile devices needed to have different UIs that work better for touch screens, and be smaller to work with 2G, 3G wireless networks.
But again, because the User-Agent is completely free-form, it could be potentially different for every permutation of manufacturer/device/OS/browser in very unique ways. How are developers supposed to handle this situation?
Through painstaking analysis and building a large database of strings, of course!
Luckily! There are open source projects that are tackling this sort of problem (as well as paid API services that do User-Agent string analysis). One is the UA-parser project, which at its core is a giant list of over 1100 regex definitions that search for unique patterns in the UA and associates it with manufacturers and specific devices. It’s a herculean effort maintained by many people.
ua-parser
ua-parser has 18 repositories available. Follow their code on GitHub.github.com
Running (up to) a thousand regex searches on a single string is obviously very resource-intensive, but this is the only way to make sure to identify a UA string to the fullest extent possible short of reading it manually.
In practice, you can speed up things massively with hashing and caching by relying on the fact that most users will have the same general default setup, so you’d only have to run regex on novel strings. This works because UA strings have a really dense cluster of exactly-matching values, and then a massively long-tail of esoteric values.
What can go wrong with using UAs?
UAs don’t have to follow the RFC formats exactly
RFCs aren’t strongly enforced in any way, so it’s entirely possible to encounter non-conforming User-Agent strings. I’ve personally seen strings where nonsense characters like newlines (\n) and ASCII nulls (\0) have been put into the string. Unicode is also technically allowed (in that systems treat is as opaque bytes) but is generally unexpected and uncommon. Most UA handlers still assume that UAs are US-ASCII (as specified in the latest RFCs)
Usually, this stuff is from someone writing a robot and they are unfamiliar with the RFCs. Or they’re trying to be jerks and attempting to break systems. Either way, when you process UA strings at scale, your code will break a surprising amount due to malformed strings, so be prepared to write exception handlers to catch bad strings.
UAs are NOT users, they’re not even unique browsers
User-Agents are ubiquitous, so many people know just a tiny bit about them. The problem comes from when those people try to interpret them and come to bad conclusions.
People sometimes think User-Agents somehow provide them with counts of users. Often this is thinking from a mix of outdated thinking from a decade ago when people often only had 1 internet-connected computer, or they’ve heard about browser fingerprinting but aren’t aware of how many data points it takes to fingerprint a browser.
Obviously, this isn’t true today. Most users these days use multiple devices/browsers throughout the day and fingerprint methods are super complex. Counts of unique UAs do give a rough sense of the number of unique types of browsers that have made requests. But even when combined with the IP address, many humans can be using multiple devices that all use the exact same UA and sit behind a NAT and share an IP.
I’ve personally had to use UAs to put very rough bounds on the minimum number of browsers used to view a site, with the raw hit count being the upper limit. This was because we literally had no other data available. But I had to be very very clear about what we were measuring.
UAs can be lies (spoofed), but as a rule most aren’t
When people hear that UAs can be spoofed easily, they often worry that they’re being lied to and their metrics are going to be off. They often worry so much they overthink things and reach for more technically difficult solutions. I often tell people not to worry about spoofing.
The primary reason is that the vast majority of users have no motivation to bother messing with their UA string. They just want to use the internet. The only people who want to manipulate their UA are usually a microscopic number of users writing bots/crawlers of some sort. Then it breaks down into a few major cases:
The UA is by a human and doing human-scale traffic. Out of hundreds, thousands, possibly millions of humans using your site every day, they’re ultimately insignificant because they represent such a fractional percent of traffic.
The UA a small volume robot — these are the small student scraper projects, the random programmer trying stuff out. So long as they’re generally well behaved and low volume, they won’t skew your metrics much so you can ignore it like the above.
It’s a significantly spammy robot — You’ll need to account for this one case somehow. Often these will hammer from small set of IPs that are often a not used by end users (like an AWS IP block or a datacenter), you can usually filter those out based on a heuristics. There are often signs of problems (like your systems overloading like it’s a DDoS attack) when you’re facing these sorts of bots.
It’s pretty rare to have to worry about spoofing unless you’re running something that robot-makers have an incentive to abuse (and UA is not likely to be the solution if that’s your problem). I suppose there are some edge cases: like if you get practically no traffic, so the bots will dominate, but you also have little reason to do a lot of analytics at that point.
Can we spot spoofed UAs?
Sooooooorta. In some very specific instances, you can catch a UA in a lie. But don’t expect it to be a regular thing.
The easiest case is when someone makes an error in spoofing their UA string. Their UA stands out like a sore thumb because no one else uses it. It could be something as simple as having an extra space or punctuation mark.
Similarly, sometimes spoofers don’t understand the User-Agent string enough and put together impossible combinations of product strings. They’ll stand out for being hyper-unique too.
Another somewhat common case is when you have access to the browser’s data via JavaScript. If you see an iPhone have a screen size that is massively different from the physical pixel dimensions of the phone itself, it’s probably lying about being a phone.
After these limited methods, the whole idea starts wandering into the realm of bot and fraud detection tech, which is a bit out of scope for here.