

Why we reluctantly work with regex
Why we reluctantly work with regex
Because, sometimes there's no choice


This week brought to you from a tweet inspired by some work I had to do a couple of months ago.

The cause of the tweet was because at work I had to write a bit of regex of medium complexity, and then run the regex against over a trillion strings via big distributed SQL engine…
There’s a pattern of joke about certain kinds of tech that goes like this: “You have a problem, you decide to use THING to solve it. Now you have two problems.” XML is usually slotted into the pattern, but Regex is a top performer here too.
But despite the cheeky jokes about Regular Expressions, a.k.a. regex or regexp, it’s almost inevitable that every data scientist will have to deal with them at least at some point in their career. There’s just too much data out there in the world that’s of a text-based nature, and we all eventually discover we a need to scan and extract bits of text from longer texts.
So what’s wrong with regex?
Lots of things, but the biggest barriers to their usage are, in no particular order:
There are multiple dialects/implementations of regex, with significant overlap but also significant differences in syntax and features. Portability is “uneven”.
The syntax is extremely dense and require lots of thinking to understand their behavior
It’s often very hard to think up all the edge cases without lots of trial and error
Some dialects of regex allow for comments, many do not
While I have a passable grasp of the more common features of regex, enough to write simple ones without opening up a reference page (gasp!), the complexity of the language often pushes me to treat all regex as write once, read never objects. Very often, I find it faster to re-implement a short-ish regex than try to figure out what an existing one does because of the concentration needed to mentally parse one carefully, character by character.
It’s no surprise that arcane strings like “^[a-zA-Z0-9_]*\.html” that take a lot of thought to understand.
import re
> s = "superfile_name.html"
> re.match('^[a-zA-Z0-9_]*\.html$',s)
<re.Match object; span=(0, 19), match='superfile_name.html'>
> re.match('^[a-zA-Z0-9_]*\.html$',".html")
<re.Match object; span=(0, 5), match='.html'>Here, this particular regex string approximately translates into human language as: “match strings that start with any number of lowercase ASCII, uppercase ASCII, numbers, and underscores (including none of those characters [aka. the empty string]), and then has “.html” at the very end, with nothing following after.
Anything that doesn’t fit that description won’t match, so if there are hyphens or spaces in the file name, no dice. The regex, like any other computer program, will dutifully follow our instructions, doing what we tell it and not what we intended in our flawed minds.
Regex can get significantly more complex than the above, incorporating things like lookbacks, look aheads, extraction groups, OR logic, and lots of other things. The feature set of regular expressions have expanded significantly over the years.
Despite the trouble we probably can’t avoid regex forever
There are more ways to search text than using regular expressions. Even within SQL, we have the much simpler (and often computationally cheaper) LIKE operator which lets us search for matching text with just literal and wildcards. Plus there are plenty of non-regex based text search algorithms in existence.
But the biggest positive for regexes is that through the power of regular languages, regexes are capable of matching infinitely many patterns at once, while most other algorithms need to target a finite set of patterns. So, depending on what we’re doing, we might just need to reach for regex, despite whatever pain it may cause us. Infinite flexibility comes with infinite potential for pain.
Surprisingly, history won’t help us
Regular readers of this newsletter will know that I love diving into the history of tech and things because they very often provide critical context that makes it much easier to understand why things that appear insane are actually the result of a logical progression. Usually that context makes it easier to reason about a topic and speeds up understanding.
Regex is NOT one of those things.
If you drag up the original paper from 1951 by S. C. Kleene (apparently pronounced /ˈkleɪni/KLAY-nee according to Wikipedia), “Representation of events in nerve nets and finite automata”, you’ll find that it’s more of a math paper formalizing an algebra for describing the behavior of neural nets using finite automata. The modern interpretation of the work is that this laid out the concept of “regular languages” (in the theoretical computer science sense of it’s a language of a fixed set of alphabet of symbols following a fixed set of rules). It ends up being that these regular languages are things that could be described using finite automata (computing machines with finite memory, as opposed to more advanced Turing machines that have infinite storage). A regular expression in this more formal context is a symbolic statement that describes a regular language.
Why would this formal computational theory math have anything to do with regular expressions of the string-matching type that we know today? Well, Ken Thompson of Bell Labs published a paper in 1968 that described an implementation of regular expressions for use in text search for a text editor on the IBM 7094. From my cursory scan of that paper, what Thompson did was take the Kleene’s concept of regular expressions and regular languages and how they translate into finite state machines, plus Kleene’s notation for such languages (which is were we get the “Kleene Star” * operator), and used it create a pattern-searching algorithm for text.
What the algorithm does is use the regular expression to compile a finite automata as described by the regex (Just-in-Time time compiling, in the ‘60s, on a mainframe!). That finite state machine is then used to scan through the characters. Since the state machine encodes the search input and current status without huge CPU and memory needs, it’s very efficient to run on 1960s computing hardware. From there, the same regex concept would make its way into UNIX tools like ed and grep, and out into countless tools and programming languages while picking up features as time progressed.
Regex is hard because you’re describing a state machine, you’re programming
While it often feels like you’re invoking an otherworldly incantation when writing regex, what we’re effectively doing is defining a complex state machine that, if the characters in a string manage to trigger the right states in the correct order, would result in a “MATCH = TRUE!” output.
What actually happens under the hood for regex is that the regular expression itself is often converted into a finite state machine before it’s applied to text. In fact, writing a basic regex engine is sometimes given as homework in computer science classes that discus formal languages and compilers.
Since there’s an actual compilation step involved, which is why packages like Python allow you to precompile a regex (via re.compile(my_regex)). It makes sense to do so when you plan on reusing the regex often and don’t want to pay the cost of compiling every time.
It’d be easier to visualize and write a state machine using declarative code, but then we’d have taken a generalize method of text search and converted it into a piece of code that targets a single pattern of text (and is likely slower than the state-of-the-art single pattern methods).
Things get harder once you get deep into the dialects
Out in the wild, you’re very likely to see references to different flavors of regex.
The base, original definition of regex only had three operations, concatenation, union (the | operator) and the Kleene star ( * ). But over time people started adding various extensions to improve the usefulness of regex. The problem was, we didn’t agree on which features to use, nor the specific syntax.
Different programming languages implemented various features over the years. Sometimes the syntax borrows heavily from a common source, such as the Perl Compatible Regular Expressions (PCRE), or the POSIX definitions of regular expressions used in things like grep and egrep. But as evidenced by this gigantic list of languages x regex features on Wikipedia, the landscape continues to be very fragmented.
Even if two languages support similar features, it’s possible that their syntax is different. For example, Python’s re module supports using \d to denote “a decimal digit, equivalent to [0-9]”, but grep and egrep only uses “[[:digit:]]” for that character class. Google’s re2 library supports both.
So you effectively have to re-learn certain bits of regex whenever you swap languages, which can lead to a certain amount of confusion. Oh, and guess what? Every database vendor had to pick and implement their own regex support over the years. So each DB will have its own flavor you need to learn!
You’d think that this would somehow be standardized in one of the many SQL standards, and you’d be right. SQL 1999 added the “SIMILAR TO” keyword that provided basic regex support, but apparently few people use it over the native regex implementations. (At least for Postgres it seems SIMILAR TO just adds an extra step to transcribe into native regex anyways so it’s always slightly slower). So while a standard might exist… it doesn’t seem to have much practical use.
My strategy for writing regex from scratch
Since regex is using a separate language to generate a machine, I approach it as a kind of mini programming exercise. Getting into the frame of mind prepares me for the many mistakes I’m going to make along the way.
This is general process I follow when I’m trying to write something for work:
Break my patterns into chunks with distinct borders
Write patterns to match the chunks individually through trial and error
Combine and stress test
For example, if I’m trying to parse a bunch of log filenames so that I can bin them by date and route them based on machine string and file extension. These are fairly well structured file names that might be autogenerated out of an app. In theory I have some control over the whole pipeline and if I really needed to, I can reformat the filenames at the source (but will avoid doing so unless I’m stuck because something else might depend on the existing filenames).
# example filenames
filenames = ['2021-05-12_machine.2-raw.log.gz',
'2021-05-10_backend-03-raw.log.gz',
'2021-04-15_frontend-25-nospam.log.5.gz']So first, I break the problem into chunks w/ clearly defined borders between sections. [ISO 8601 date]_[machine name.number]-[log type].[extension].gz
ISO date chunk
This one is fairly easy, since ISO 8601 guarantees that things are formatted as yyyy-mm-dd. We can simply brute force it. We also know that the underscore immediately following the date is fixed, and so it should be easy to integrate whatever we come up with into the final regex.
> import re
> iso = '2021-06-13'
# Straight up literal
> re.search('\d\d\d\d-\d\d-\d\d',iso)
<re.Match object; span=(0, 10), match='2021-06-13'>
# We can use the {m} repeat feature, it is *1* character shorter
> re.search('\d{4}-\d{2}-\d{2}',iso)
<re.Match object; span=(0, 10), match='2021-06-13'>
# Since date and months are -##, we could repeat that chunk
# But this is digustingly hard to read. not recommended
> re.search('\d{4}(-\d{2}){2}',iso)
<re.Match object; span=(0, 10), match='2021-06-13'>The machine chunk
This chunk represents machine hostnames, and there are numbers to them because we have multiple machines. This gets messier because for some reason, the machine names can have dots (machine.2) or dashes (frontend-25) in them.
But we’ll make the assumption that all machine names follow certain rules: 1) names are in ascii alphabet or underscores, no numbers, no spaces, and 2) the machine number can be any number of digits, but it HAS to have a at least one digit.
> machines = ['machine.2','backend-03','frontend-25']
> [re.search('[\w_]+[.-]\d+',x) for x in machines]
[<re.Match object; span=(0, 9), match='machine.2'>,
<re.Match object; span=(0, 10), match='backend-03'>,
<re.Match object; span=(0, 11), match='frontend-25'>]Here we make use of the square brackets to say only characters within the brackets (\w = alphabet, and underscore) can match. We use the + symbol to say it should match one or more characters of the preceding symbol (which is our bracket list of allowable symbles). After the machine name, we expect ONLY exactly one period or hyphen, followed by one or more digits.
Log type and extension chunks
Log type is fairly simple, it’s just a alphanumeric text with no spaces that says “raw” or “nospam”, etc. Same goes for the file extension.
types = ['log','nospam','textv21']
> [re.search('[\w\d]+', t) for t in types]
[<re.Match object; span=(0, 3), match='log'>,
<re.Match object; span=(0, 6), match='nospam'>,
<re.Match object; span=(0, 7), match='textv21'>]
# sometimes we have rotated logs with numbers
> extensions = ['log.gz','log.5.gz']
# So add in a (\.\d+)? bit to say "there's an optional .# piece"
> [re.search('[\w\d]+(\.\d+)?', t) for t in types]
[<re.Match object; span=(0, 3), match='log'>,
<re.Match object; span=(0, 5), match='log.5'>]
Putting it all together
# Glue all the regex pieces together, putting them in () to tell the regex we want those specific patterns output as a group later
# Use the fixed border characters (underscore, hyphen, period, .gz)
regex = '(\d{4}-\d{2}-\d{2})_([\w_]+[.-]\d+)-([\w\d]+)\.([\w\d]+)(\.\d+)?.gz'
filenames = ['2021-05-12_machine.2-raw.log.gz',
'2021-05-10_backend-03-raw.log.gz',
'2021-04-15_frontend-25-nospam.log.5.gz']
> [re.search(regex,f) for f in filenames]
[<re.Match object; span=(0, 31), match='2021-05-12_machine.2-raw.log.gz'>,
<re.Match object; span=(0, 32), match='2021-05-10_backend-03-raw.log.gz'>,
<re.Match object; span=(0, 38), match='2021-04-15_frontend-25-nospam.log.5.gz'>]
# And show the groups we collected
> [re.search(regex,f).groups() for f in filenames]
[('2021-05-12', 'machine.2', 'raw', 'log', None),
('2021-05-10', 'backend-03', 'raw', 'log', None),
('2021-04-15', 'frontend-25', 'nospam', 'log', '.5')]
Finally, we have all our pieces in place, so we build our giant mega regex out of it. But ugh, that resulting regex string is an ugly mess. BUT LUCKILY! Python let’s us have verbose regex! (Source: Dive into Python 3)
# verbose regex ignores whitespace and
commented = """(\d{4}-\d{2}-\d{2}) #date piece
_ # date separator
([\w_]+[.-]\d+) # machine name, allows for one hyphen or dot
- # hyphen separating machine name and log time
([\w\d]+) # logtype, alphanumeric, no spaces
\. # period between logtype and extension
([\w\d]+) # extension
(\.\d+)? # optional log rotation number
.gz # fixed, we gzip everything
"""
# IMPORTANT, you must invoke the re.VERBOSE flag or it doesn't work
> [re.search(commented,f,re.VERBOSE).groups() for f in filenames]
[('2021-05-12', 'machine.2', 'raw', 'log', None),
('2021-05-10', 'backend-03', 'raw', 'log', None),
('2021-04-15', 'frontend-25', 'nospam', 'log', '.5')]It’s a really nice feature for documenting extremely complicated regex, but you have to know its quirks, including knowing to invoke re.VERBOSE in the regex function call.
Whitespace is ignored. Spaces, tabs, and carriage returns are not matched as spaces, tabs, and carriage returns. They’re not matched at all. (If you want to match a space in a verbose regular expression, you’ll need to escape it by putting a backslash in front of it.)
Comments are ignored. A comment in a verbose regular expression is just like a comment in Python code: it starts with a
#character and goes until the end of the line. In this case it’s a comment within a multi-line string instead of within your source code, but it works the same way.
Learning to cope with regex
From the long example I created, it’s obvious that writing regex is difficult. And as with any difficult problem, people tried to improve the experience for ages.
One popular tool is Regexer. It’s a tool that lets you paste in example text, and then build out regex for the Javascript and PHP/PCRE dialects. It has a nice explainer feature which you can also use to understand what an existing regex string is doing without having to remember all the special symbols involved. Tools like these lighten the mental load needed to make sense of regexes.
Another tool, Regex Generator, takes an example string and generates a clickable interface where you can mark certain predefined chunks of text that the generator will piece together for you. It’s similar to my manual process, but uses heuristics to figure out where the chunks are. Obviously, my own human method is more precise simply because I can chunk things better than a predefined heuristic can.

More recently, there have been a new class of tools being made: AI powered regex generators, one example of which is RegexGenerator++. The basic idea of the tool is you give it a bunch of example strings and tell the tool what you would like to extract out of the examples. In this 2015 paper, Bartoli, De Lorenzo, Medvet, and Tarlao describe using genetic programming algorithms to solve the problem.
The genetic algorithm process isn’t perfect though, if you read the paper the system is splitting up all the input, building regexes to solve each one separately, and then bringing things together at the end. It’ll combine different regex strings it’s unable to combine with OR operators at the end. while the tool is likely to get you something that works for the examples you give it, it’s a bit brute-force-y and you’ll still have to check the resulting regex to see if it’s suitable for your needs.
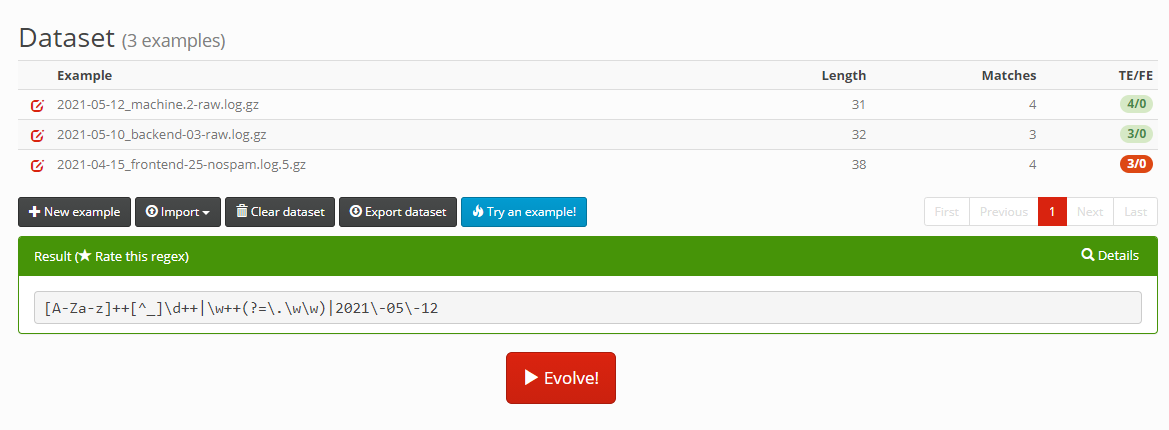
As with many AI problems, novel input and unexpected edge cases can be your downfall. It’s a cute idea, and I think given enough curated examples, the approach might generate a useful regex. But with a mere 3 examples, it very quickly overfitted in a bizarre way.
Long story short, there’s still no magic bullet. You’re going to have to learn bits of regex someday.
Sorry.
About this newsletter
I’m Randy Au, currently a Quantitative UX researcher, former data analyst, and general-purpose data and tech nerd. The Counting Stuff newsletter is a weekly data/tech blog about the less-than-sexy aspects about data science, UX research and tech. With occasional excursions into other fun topics.
All photos/drawings used are taken/created by Randy unless otherwise noted.
Supporting this newsletter:
This newsletter is free, share it with your friends without any guilt!
But if you like the content and want to send some love, here’s some options:
Tweet at me - Comments and questions are always welcome, they often inspire new posts
A small one-time donation at Ko-fi - Thanks to the folks who occasionally send a donation! I see the comments and read each one. I haven’t figured out a polite way of responding yet because distributed systems are hard. But it’s very appreciated!!!